
 Dans le monde Big Data, rapidement se pose un certain nombre de besoins.
Dans le monde Big Data, rapidement se pose un certain nombre de besoins.
Besoins qui, pris unitairement, sont déjà complexes à résoudre mais qui, mis bout à bout, s’avèrent encore plus difficiles à intégrer.
Parmi ces besoins, on peut citer, par exemple, les besoins de qualité de données ou de linéage (problématiques qui peuvent être regrouper sous le terme de data governance).
Cet article n’a pas pour objectif de fournir une solution clé en main ni de parler d’outils déjà existant mais plutôt de poser différentes réflexions que j’ai pu avoir afin de savoir si elles avaient un sens…
Besoins
Lorsque l’on est confronté au Big Data, les besoins qui en découlent sont les suivants :
- avoir un scheduler scalable permettant d’exécuter et ordonnancer les différents jobs (qu’ils soient MapReduce, Spark, Hive ou autres) mais également exécuter des actions qui leurs sont associées (déplacement de fichiers/répertoires, création/suppression/modification de tables hive, création de fichiers _SUCCESS, appliquer une politique de rétention, etc.)
- avoir un catalogue de données (afin de connaître ses datasets) pour pouvoir retrouver l’information
- disposer d’un lineage de données (afin de pouvoir savoir à partir de quel dataset est issu tel autre)
- avoir de la qualité de données
A noter que quand il est fait mention de scheduler, il ne s’agit pas de cluster manager comme Yarn, Mesos ou k8s mais d’un orchestrateur de tâches comme Oozie ou Airflow (pour ne citer qu’eux).
Si nous revenons plus précisément sur certains de ces points, le lineage de données et la qualité de données méritent qu’on s’y arrête un peu plus longtemps.
Concernant le lineage de données, cela est intéressant de savoir à partir de quel dataset un dataset est issu mais il peut également être utile de disposer d’un lineage de traitement, c’est-à-dire savoir quel job a produit quel dataset. En effet, cela permet de facilement savoir, si un dataset a, par exemple, mal été produit, quel est le job dans la chaîne qui est fautif.
De même, dans un contexte de véracité ou d’audit, pouvoir prouver que tel traitement produit bien le résultat voulu peut être primordial.
En outre, en plus d’avoir un lineage de données portant sur le dataset, il peut être intéressant d’avoir un lineage de données portant sur le contenu du dataset. En effet, connaître la propagation d’une information (ou d’un champ) de manière plus fine peut être nécessaire.
Pour ce qui concerne la qualité de données, cela lève différentes interrogations :
- que faire lorsque la donnée produite ne respecte pas le contrat (car oui, il s’agit bien d’un contrat au sens pré-condition/post-condition) :
- doit-on arrêter la chaîne de traitement?
- doit-on lever une alerte et continuer le traitement? et si oui, que faire de la donnée ignorée/mal produite (doit-on faire une dead letter queue sur la donnée en amont ou en aval?, quelle est la politique de traitement de cette dead letter queue?, etc…)?
- doit-on être pro-actif (ie. faire une vérification avant/après l’exécution de la transformation) ou le faire de manière lazy/asynchrone?
- comment doit être exprimé le contrat et qui (au sens traitement) doit vérifier la véracité de ce dernier?
- si une même opération doit être appliquée sur différents datasets à différentes étapes du pipeline de traitement, comment s’assurer qu’elle soit consistante (ie. exécuter de la même manière) et cela malgré l’utilisation de différentes technologies?
A noter que lorsqu’il est fait mention de qualité de données, il s’agit surtout de vérifier la consistance de la donnée sur un périmètre restreint et simple.
En effet, y intégrer des vérifications plus larges tels que des règles métiers, un croisement de différents datasets ou même d’y appliquer un modèle issu de machine learning sort du périmètre de cet article et s’avère difficile à exprimer.
En outre, de tels traitements sont généralements réalisés à posteriori.
Bref, plus de questions que de réponses… mais qu’il est important de se poser.
Aussi, le besoin peut maintenant être exprimé de la manière suivante :
- avoir un scheduler
- avoir un catalogue de données
- disposer d’un lineage de données au niveau du dataset
- disposer d’un lineage de données au niveau du champ
- disposer d’un lineage de traitement
- avoir de la qualité de données :
- disposer d’un moyen pour exprimer le contrat à respecter
- disposer d’un moyen pour exprimer le comportement à avoir si le contrat n’est pas respecté
Constat
Scheduler
Si on revient sur la partie scheduler, un constat peut être fait concernant les solutions les plus souvent utilisées/connues (airflow ou oozie pour n’en citer que quelques-unes) : elles sont verbeuses (au sens don’t repeat yourself).
Afin de permettre à l’orchestrateur de calculer/représenter son DAG (Directed Acyclic Graph) d’exécution, il faut :
- indiquer/représenter les input et output des jobs
- ajouter les pre/post actions à exécuter (à noter que la vérification des conditions de l’exécution d’un job peut être vu comme un pré-action)
Pourtant, devoir indiquer/représenter les input/output d’un job est déjà exprimé dans le job en lui-même (par exemple, si on prend un job Spark, afin de pouvoir consommer/produire un RDD/DataSet/DataFrame, il faut effectuer une opération de lecture/écriture explicite. De même pour une requête SQL où ces informations apparaissent).
Concernant les pre/post actions, une grande majorité d’entre elles peuvent être déduite du job : par exemple, on ne peut lire une donnée non présente. Ainsi devoir l’exprimer au niveau du scheduler est redondant.
De même si on sait que le job doit créer/ajouter la partition hive pour la donnée produite, devoir le re-préciser pour chaque job au niveau du scheduler est dommageable.
Si un alter table hive (dans le cas où un nouveau champ venait à être produit) ou une politique de rétention doivent être effectués, nous y reviendrons un peu plus tard… 😜
Bref, on peut donc constater que la majorité des choses qui doivent être exprimées dans le scheduler sont redondantes.
Catalogue de données
Le catalogue de données permet de connaître l’ensemble des datasets du système. Afin de le peupler, plusieurs approches sont possibles :
- utiliser directement le metastore hive comme étant le catalogue de données
- dissocier le catalogue de données du métastore hive
Dissocier le catalogue de données du métastore hive apporte plusieurs avantages :
- le découplage
- la possibilité d’ajouter d’autres types d’informations plus méta que ce qui est permis via le metastore (documentation, …)
Cependant, cela demande à avoir à le maintenir/synchroniser et, pour cela, plusieurs approches sont possibles :
- une approche lazy c’est à dire un mécanisme allant scruter le metastore hive (que cela soit fait en positionnant un listener directement sur ce dernier ou via un job allant l’interroger)
- une approche plus invasive qui consiste à coupler fortement les jobs en leur demandant d’aller renseigner le catalogue de données
- une approche entre deux qui consiste à s’appuyer sur l’observabilité des jobs
En outre, vient se poser la question de la véracité du métastore hive. En effet, le metastore hive est une projection du dataset qui peut être incomplète puisqu’on est en fonctionnement schema on read. Le dataset réel peut donc être plus complet que ce qui est déclaré dans le metastore (le cas des view n’est, ici, pas pris en compte) (à noter que l’utilisation de SparkSQL permet de réduire la chance de diverger).
Linéage de données
Le lineage de données est une problématique non triviale et est parfois faite de manière déclarative (et donc non à jour…).
Cependant, les jobs disposent de l’information et il est donc possible de ré-aggréger cette dernière de manière pro-active ou non afin de disposer d’un linéage (au moins le lineage de dataset).
Bien sûr disposer de nombreuses technologies de traitement rend cela plus complexe.
Une autre approche pourrait consister à corréler les accès au metastore hive et le plan d’exécution des jobs mais il se pose alors la même question de la complétude de l’information que pour le catalogue de données.
Concernant le linéage de données au niveau champ, cela s’avère assez compliqué.
Linéage de traitement
Disposer d’un linéage de traitement complet (ie. pas seulement avec une vision d’un workflow donné) peut s’avérer complexe avec les scheduler actuels.
En outre, si plusieurs technologies de scheduler sont utilisées ou si il en existe plusieurs instances, le manque d’API/interface commune rend l’extraction et la corrélation difficile.
Qualité de données
La qualité de données est souvent effectuée a posteriori sur les datasets avec présentation des résultats sous forme de dashboard et/ou possibilité d’envoie d’alertes.
Cela permet d’éviter d’avoir un arrêt de la chaîne de traitement mais cela induit qu’il faut re-traiter toute la donnée corrompue.
Pour ce faire, il devient alors utile/indispensable de disposer du linéage de données (au minimum dataset).
Une fois l’ensemble des datasets à re-produire en main, il faut alors en déduire les jobs qu’il faut relancer et re-scheduler ces derniers (après une éventuelle correction) ou un sur-ensemble si le scheduler ne permet pas une exécution unitaire.
Si la qualité de données est effectuée de manière défensive (ie. qu’un job ne s’exécute que si ses pre/post conditions sont respectées) cela peut permettre :
- une consommation moindre de ressource de calcul (le dataset est lu et traité moins souvent)
- d’éviter d’avoir à re-processer un ensemble de datasets corrompus
Cependant, il se pose la question des données de qualité. En effet, il s’agit souvent de données aggrégées (somme, moyenne, nombre d’occurence, …). Il convient alors de les stocker et de les rendre accessibles aux jobs en ayant besoin afin d’éviter de les recalculer.
Une autre question qui doit être posée est le couplage entre la génération de ces métriques de qualité et le traitement du job. Faut-il que le job produise ces données ou peut-on la voir comme une décoration du job?
Proposition
On a pu constater un certain nombre de points dans le paragraphe précédent (de manière totalement subjective et biaisé 😄).
Concepts
Dans cette partie, on va tenter de ré-assembler les morceaux au moins d’un point de vue conceptuel…
Concernant le scheduler, on peut le voir de manière centrale. En effet, il a connaissance de nombreuses informations.
Pour la partie duplication d’informations entre les jobs et leurs actions qui leur sont associées, si il était capable d’introspecter le job, il serait presque possible de n’avoir aucune information superflue à lui donner.
Si l’ajout magique d’une action n’était pas souhaitable, il est tout à fait possible d’imaginer un mécanisme de décorateur (au sens design pattern) qui permettrait d’ajouter un comportement au job et qui irait l’introspecter afin de découvrir la majorité des paramètres nécessaire à son fonctionnement.
Les informations dont le scheduler disposeraient alors permettrait de répondre :
- au linéage de données (du point de vue dataset)
- au linéage de traitement
Concernant le catalogue de données, si il est vu découplé du metastore hive et si on considère que le schéma réel du dataset n’est pas porté par le metastore hive mais par un autre format exhaustif (comme parquet, avro, protobuf), on obtient alors la notion de schema registry.
Ce schema registry deviendrait alors la source de vérité sur les datasets et chaque dataset alors consommé/produit devrait être connu de ce dernier et associé au format choisi (parquet, avro, protobuf) mais également à ses meta-données (localisation hive, etc). Le scheduler ou le job devrait alors y accèder et il deviendrait alors possible de connaître les champs consommés et produits. En effet, si chaque input/output du job dispose de sa propre déclaration au niveau du schema registry, alors par construction, on connait les champs consommés/produits. Il devient alors possible de disposer du linéage de données avec la granularité champ.
Pour ce qui concerne les actions de type application d’une politique de rétention ou altération du schema hive (dans le cas où un nouveau champ venait à être produit), il revient au schema registry d’appliquer ces dernières. En effet, la politique de rétention peut être vu comme une metadonnée du dataset alors que l’application d’un changement de schéma au niveau hive n’est qu’une conséquence d’un changement de schéma au niveau du schema regsitry. Ces opérations n’ont pas à être portées par des pre/post actions du job mais c’est bien de la responsabilité du schema registry dont il est question.
Enfin pour la qualité de données, si on considère que les pré/post condition ne sont que le résultat de la vérification d’un contrat sur le dataset (ce dont il s’agit réellement), alors cette information devrait être associée aux metadonnées du dataset et donc portée et exprimée au niveau du schema registry.
Cependant, puisqu’il s’agit de métadonnées, il est alors plus naturel d’exprimer le contrat que doit respecter le dataset en mode descriptif et non via un mode impératif.
D’un point de vue exécution, ce calcul de données aggrégées et la décision de savoir quel comportement adopté dans le cas où le contrat n’est pas respecté pourrait être du ressort du scheduler en décorant le job au même titre qu’il est décoré par les actions comme l’ajout de partition hive.
Cependant, afin de s’assurer que le contrat et la politique sont appliqués de manière cohérente, il convient alors de traduire le modèle descriptif en une liste d’action à effectuer (comme la calcul de métrique, l’arrêt de la chaine de traitement, etc.). Ainsi, cela permet de s’assurer qu’une même politique et qu’un même contrat seront appliqués de manière homogène dans tout le pipeline de traitement.
Il peut également être envisagé de considérer les metriques aggrégés de qualités comme des metadonnées associées au dataset.
Détails d’implémentation à prendre en considération
Dans le cas d’un scheduler qui serait multi-tenant et unique, l’ensemble des informations dont il dispose est facilement disponible. Cependant si il est mono-tenant et/ou si il en existe plusieurs instances, alors ils doivent être interopérable et remonter leurs informations au sein d’un service plus global qui aurait à sa charge l’aggrégation et la mise à disposition des informations (dont le DAG global d’exécution).
En outre, si le scheduler est multi-tenant, il doit prévoir la notion de namespace afin de gérer les problématiques de sécurité, de priorité, etc.
De même, il doit être capable d’éviter les phénomènes de famine en disposant de scheduler permettant la préemption d’exécution de jobs en prenant éventuellement en compte cette notion de namespace.
Concernant son design, il doit bien sûr être scalable, fournir les métriques nécessaires à son monitoring/supervision.
Il devrait également disposer d’exécuteurs indépendants et autonomes pilotés par un manager afin de permettre la résilience des exécutions et et la bonne exécution des jobs/actions (en gérant les retry ou en tuant une action bloquée par exemple)
Concernant la mise en oeuvre de l’introspection des jobs permettant au scheduler de connaître les informations dont il a besoin afin de déterminer le graphe d’exécution ainsi que les éventuels pre/post actions, elle pourrait être faite via un système de SPI (Service Provider Interface) couplé à un mini wrapper ou l’ajout d’annotation sur les opérations de lecture/écriture par exemple.
Concernant les informations de linéage de données et de traitement produite par le scheduler, elles pourraient être aggrégées et mise à disposition par un service tierce afin de permettre la séparation of concerns.
Pour connaitre le linéage de données avec la granularité champ, étant donné que l’information est produite en scrutant les jobs qui accèdent au schema registry, cette remonté d’accès aux datasets pourraient être faite à destination d’un service tierce via un système de hook, listener. Ce service tierce (qui pourrait être le même service que celui utilisé pour le lineage de données et de traitement) serait alors en charge de leur aggrégation et de leur mise à disposition.
Exemple
Afin de tenter d’illustrer de manière plus concrète tout ce long blabla, prenons un exemple.
Supposons qu’on dispose d’un dataset d1 à partir duquel est produit le dataset d2 via le job J écrit en SparkSql.
d1 dispose de 2 colonnes : d1_c1 et d1_c2 de type int.
d2 dispose de 1 colonne : d2_c1 (de type int) qui contient toutes les lignes de d1_c1 mais qui remplace toutes les valeurs négatives par 0
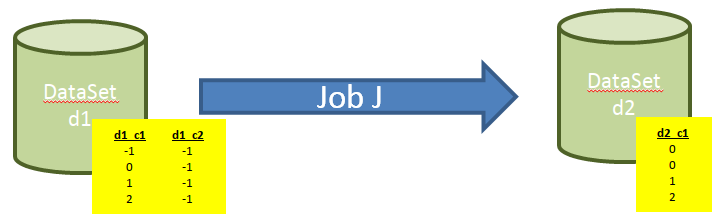
Supposons que le schema registry utilise le format avro pour décrire les données et que le metastore de hive soit utilisé.
Supposons également qu’on représente la qualité de données dans ce cas avec un pseudo langage type:
d2.count(*) == d1.count(*)
d2.d2_c1 >= 0
Dans ce cas, la déclaration dans le schema registry de d1 et d2 aurait pour conséquence la création de la database et des tables dans le metastore hive automatiquement.

Concernant le job de traitement, on pourrait avoir dans sa version original :
val spark = SparkSession
.builder()
.appName("job J in Scala")
.enableHiveSupport()
.getOrCreate()
val d1 = spark.sql("SELECT d1_c1 FROM d1")
val d2 = df.withColumn("d2_c1", when(col("d1_c1") < 0, 0) otherwise col("d1_c1")).select("d2_c1")
d2.write.format("csv").save("hdfs://localhost:20112/test/d2")
et dans sa version modifiée permettant l’introspection par le scheduler
val spark = SparkSession
.builder()
.appName("job J in Scala")
.enableHiveSupport()
.getOrCreate()
val d1 = ReaderWrapper(spark, "d1", "d1_c1")
val d2 = df.withColumn("d2_c1", when(col("d1_c1") < 0, 0) otherwise col("d1_c1")).select("d2_c1")
WriterWrapper(spark, d2, "d2")
A cette étape, on a donc :
- les datasets déclarés dans le schema registry ainsi que la définition du contrat de qualité
- les databases et tables hive automatiquement créés dans le metastore hive
Lors de l’ajout du job J au sein du scheduler, ce dernier est alors capable de :
- introspecter le nouveau job J
- en déduire les nouveaux noeuds d1 et d2 ainsi que le lien J qui les relie
- reconstruire son DAG d’exécution afin de prendre en compte cette nouvelle dépendance
- déduire que pour exécuter J, il nécessite d’avoir de la donnée pour le dataset d1 entrainant, par exemple, le positionnement d’un listener au niveau du metastore hive afin de savoir si un changement se produit sur le dataset d1 (ajout d’une partition par exemple)
- grâce à l’ajout du noeud d2, en déduire qu’il doit aller requêter le schema registry pour y trouver éventuellement un nouveau contrat de qualité
- traduire ce nouveau contrat:
- en une pré-action à l’éxécution du job J permettant de lancer un job de calcul du nombre de ligne sur d1
- en une post-action à l’éxécution du job J permettant de lancer un job de calcul du nombre de ligne sur d2 ainsi que de vérifier qu’il n’y a pas de valeurs négatives pour la colonne d2_c1
- une fois le job J exécuter, aller vérifier que les métriques aggrégées produites répondent bien aux attentes.
Lors de l’exécution du job J, l’accès au schema registry permet de savoir que la colonne d1_c1 de d1 a été consommé afin de produire la colonne d2_c1 de d2 permettant ainsi de fournir l’information au service s’occupant d’aggréger les informations pour fournir le lineage de données.
A noter que lors de l’instrospection du scheduler du job J, cette information de lineage pourrait également être déduite avant même l’exécution du job J.
Concernant le lineage de traitement et de données d’un point de vue dataset, il suffit simplement que le scheduler remonte l’information au service de lineage.
Conclusion
Dans cet article, j’ai essayé de poser un certain nombre de besoins qui sont généralement présents dans les projets Big Data ainsi que les constats que j’ai pu faire et une proposition (qui vaut ce qu’elle vaut…) pour ré-assembler ces différents points.
L’approche que j’ai aimé avec ma proposition est que, je trouve, qu’au final, il y avait une certaine forme de cohérence un peu comme les pièces d’un puzzle qu’on emboite… avec en son centre le scheduler 😜
Bien sûr tous ces points sont discutables et c’est d’ailleurs la raison pour laquelle j’ai posé mes réflexions dans cet article afin de fournir un matériel à partir duquel il sera possible de débattre/échanger/discuter si le coeur vous en dit 😉
Enfin, pour finir, je tenais à remercier Florent, DuyHai et Bruno pour leur relecture et leurs remarques pertinantes. 😙