
 Cet article fera un rapide tour d’horizon sur les différentes stratégies qui peuvent être utilisées pour Logstash.
Cet article fera un rapide tour d’horizon sur les différentes stratégies qui peuvent être utilisées pour Logstash.
Pour ce faire, je m’appuierai sur le très bon livre officiel que je me suis procuré (moyennant environ 10€) et qui fournit une très bonne vision sur ce qui est possible de faire ainsi que sur les différents concepts mais également sur les différentes stratégies de déploiement.
Même si je résumerai succinctement quelques-uns des concepts afin que cet article soit un minimum compréhensible, cet article traitera surtout sur la façon dont il est possible de déployer les agents Logstash.
[ndlr : par contre, je ne ferai, comme à mon habitude, que retranscrire ce qui est présent dans le livre…]
Les concepts
Logstash est écrit en JRuby et fonctionne dans une JVM. Son architecture est orientée messages et est très simple. Plutôt que de séparer le concepts d’agents et de serveurs, Logstash se présente comme un simple agent qui est configuré pour combiner différentes fonctions avec d’autres composants open souce.
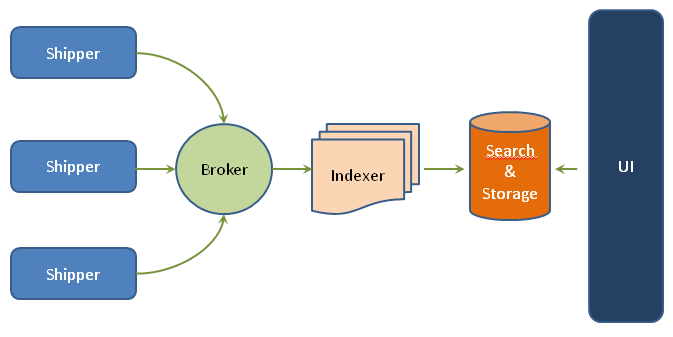
L’écosystème de Logstash est constitué de 4 composants :
- Shipper qui envoie des événements à Logstash.
- Broker et Indexer qui reçoivent et indexent les événements.
- Search et Stockage qui permettent de rechercher et de stocker les événements.
- Web Interface qui est une interface web appelée Kibana.
Les serveurs Logstash sont constitués d’un ou de plusieurs de ces composants indépendamment, ce qui permet de les séparer offrant ainsi la possibilité de scaler mais également de les combiner en fonction du besoin.
Dans le plupart des cas, Logstash sera déployé de la manière suivante :
- Les hôtes exécutant les agent Logstash comme des Shipper qui émettent, comme des événements, les logs des applications, services et hôte à un serveur central Logstash. Ces hôtes n’ont besoin de disposer que d’agents Logstash.
- Le serveur central Logstash qui aura à sa charge l’exécution du Broker, Indexer, Search, Storage et Web Interface afin de recevoir, processer et stocker les logs.
En fait, une configuration typique de Logstash est la suivante :
input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
où :
inputpeut prendre en valeur des plugins qui correspondent à ce que peut prendre en entrée l’agent (comme, par exemple, l’entrée standard ou le contenu d’un fichier).filterpeut prendre en valeur des plugins qui permettent de manipuler l’événement en le parsant, filtrant ou en ajoutant des informations issues du parsing ou non.outputpeut prendre en valeur des plugins qui permettent de préciser où seront envoyés les événements (comme, par exemple, la sortie standard ou ElasticSearch).
Les différentes stratégies de déploiement possibles
Le mode de déploiement classique
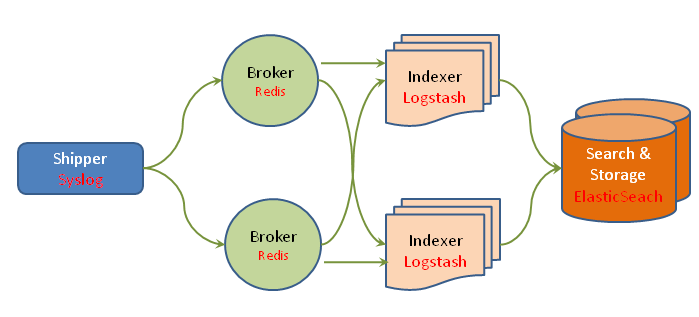
Dans l’architecture de déploiement classique, on retrouve la stack préconisée qui est la suivante :
- Les agents Logstash se trouvant sur les machines hôtes collectent et émettent les logs (sous forme d’événements) au système central.
- Une instance d’un système de bufferisation (comme Redis ou autre, comme une implémentation d’AMQP) reçoit les événement sur le serveur central et joue le rôle de buffer.
- Un agent Logstash extrait les événements de logs du buffer et les traite.
- L’agent Logstash envoie les événements d’index dans ElasticSearch.
- ElasticSearch stocke et rend les événements cherchable.
- Kibana permet la recherche et le rendu des événements indexés dans ElasticSearch.
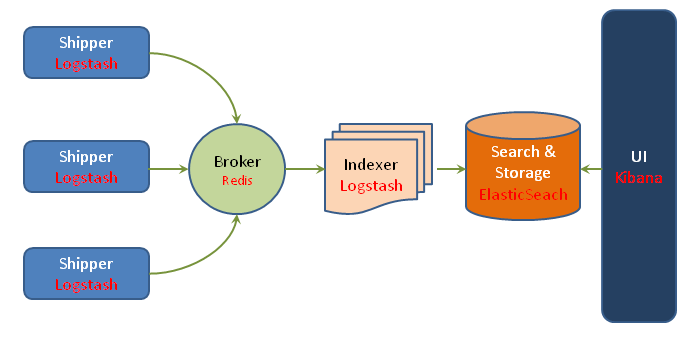
En fait, le broker permet de servir de buffer entre les agents et le serveur Logstash. Cela est essentiel pour les raisons suivantes :
- Cela permet d’améliorer les performances de l’environnement Logstash en fournissant une buffer de cache pour les événements de log.
- Cele permet de fournir de la résiliance. Si l’indexation Logstash échoue, alors les événements sont mise en fils d’attente afin d’éviter la perte d’informations.
On observe donc, dans cette configuration, que les agents Logstash présents sur les machines hôtes ne font que transmettre sans intelligence réelle au buffer les différents événements de log et qu’ils n’ont pas vraiment de logique (ie. ils n’ont pas de section filter mais juste les sections input et output).
Le mode de déploiement sans agent
A la mode système
Comme on a pu voir dans le paragraphe précédent, les machines hôtes disposent d’un agent Logstash complet. Cependant, ils n’ont pas vraiment de logique puisqu’ils ne font que transmettre les événements de logs au broker dont le rôle est de servir de buffer.
Cependant, parfois, il peut être intéressant de ne pas à avoir besoin d’installer un agent Logstash sur les machines hôtes :
- si la JVM déployé sur la machine hôte est limitée,
- si la machine hôte est un périphérique qui dispose de peu de ressource et qu’il n’est pas possible d’y installer une JVM ou d’exécuter un agent,
- s’il n’est pas possible d’installer n’importe quel logiciel sur la machine hôte.
Pour répondre à cette problématique, il est possible d’utiliser des outils systèmes comme Syslog.
Dans ce cas, le serveur Logstash n’aura qu’à déclarer un input supplémentaire permettant d’écouter des événéments (dans notre cas, Syslog).
A titre informatif, il est possible d’utiliser un Appender syslog dans log4j ou logback (entre autre).
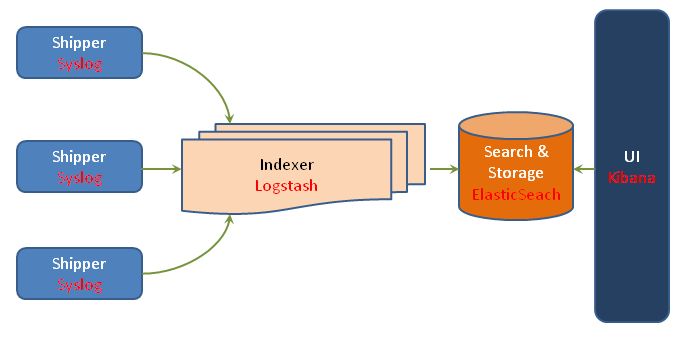
A la mode agent
Dans le cas où ni un agent Logstash ni Syslog ne sont envisageables, il est possible d’utiliser Logstash Forwarder (anciennement Lumberjack).
Il s’agit d’un client légé permettant d’envoyer des messages à Logstash en offrant un protocole maison intégrant de la sécurité (encryption SSL) ainsi que de la compression.
Il a été conçu pour être petit avec une faible emprunte mémoire tout en étant rapide. Il a été écrit en Go.
Dans ce cas, il suffit d’exécuter logstash-forwarder avec les bons fichiers de configuration spécifiant l’adresse du serveur cible ainsi que l’emplacement du certificat et les fichiers à scruter.
Du coté serveur, il suffit, tout comme pour le mode sans agent à base de Syslog, de déclarer un input lumberjack.
A noter que d’autres shipper sont également disponibles tels que :
Les filtres
Logstash vient avec un système de filtre qu’il est possible de configurer via la section filter.
Ces filtres permettent de filtrer mais également de modifier (via mutable) le contenu de l’événement. Ils permettent également de parser les événements (via grok) afin de les rajouter lors de la phase d’indexation (et donc de stockage). Cela permet ainsi de pouvoir rechercher des événements de manière plus ciblé.
Il existe plusieurs stratégies lors de l’utilisation de filtres :
- filtrer les événements sur l’agent,
- filtrer les événements sur le serveur central,
- émettre les événements au bon format.
Le plus simple est encore d’émettre les logs au bon format, cependant, cela n’est pas toujours possible (trop de log différents, systèmes hétérogènes, code legacy, …).
Une autre manière de faire est d’exécuter le filtrage localement (ie. directement sur l’agent). Cela permet de réduire la charge de traitement du serveur central et d’être sûr que seuls les événements propres et structurés seront stockés. Cependant, cela oblige à maintenir une configuration plus complexe sur chaque agent.
A l’inverse, si le filtrage est effectué sur le serveur central, cela permet de centraliser les filtres et permet donc une administration plus simple. Cependant, cela demande des ressources supplémentaires pour effectuer le filtrage sur un plus grand nombre d’événements.
La scalabilité et Logstash
Une des grande force de Logstash est qu’il est possible de le composer avec différents composants : Logstash lui-même, Redis comme broker, ElasticSearch et bien d’autres éléments qu’il est possible de composer via la configuration de Logstash.
Ainsi, il est possible de jouer à plusieurs niveaux pour répondre à telles ou telles problématiques comme la perte de messages, le fait d’avoir un SPOF (Single Point Of Failure) ou d’avoir un point de contention dans le système.
Par exemple, si Redis est utilisé comme broker entre les agents Logstash et le serveur central, il peut être intéressant de passer Redis en mode failover afin d’éviter une perte d’événements lors de la transmission de ces derniers. Pour ce faire, il suffit de configurer le plugin redis de la section output avec l’option shuffle_hosts pour indiquer à l’agent Logstash de n’utiliser qu’un seul noeud Redis lors de sa phase d’écriture. Du coté du serveur central, il suffit d’ajouter (et de configurer) autant de plugin redis de la section input que de noeud.
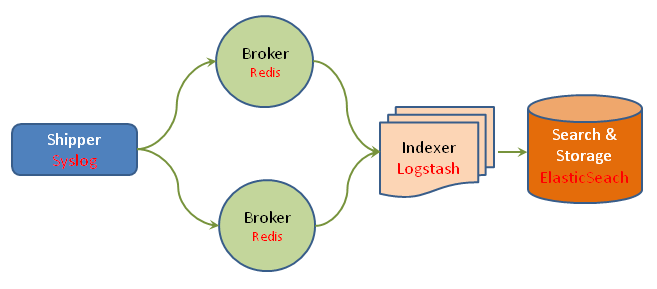
Afin de permettre à la partie stockage/indexation d’être scalable, il suffit de configurer ElasticSearch en mode cluster, ce qui est natif chez lui.
Enfin, il est possible de rendre le serveur central Logstash robuste à la panne en en créant d’autres instances (mode failover) qui partageront la même configuration.
Conclusion
En conclusion de cet article où je ne suis pas rentré dans les détails (mais ce n’est pas ce qui m’intéressait…), on peut constater qu’il existe moultes façons de configurer Logstash (et son écosystème) qui dépendent à chaque fois des besoins.
Cela est rendu possible par l’architecture et la conception modulaire de Logstash et le fait qu’il est très simple de le plugger à différentes solutions.
Même si cela est évident, je trouvais utile de le marquer noir sur blanc dans un court article… ;-)
Pour aller plus loin…
- http://logstash.net/
- http://www.logstashbook.com/
- http://blog.xebia.fr/2013/12/12/logstash-elasticsearch-kibana-s01e02-analyse-orientee-business-de-vos-logs-applicatifs/