
![]()
De nombreuses applications ou systèmes d’informations nécessitent le chargement de données issues de fichiers.
Bien souvent, cet import est exécuté par batch, mais il peut aussi être intéressant de faire cet import au fil de l’eau.
En outre, bien souvent, les fichiers à importer sont, soient nombreux, soient volumineux. Du coup, écrire un code simple et fiable peut devenir plus ardu que ce qu’il n’y parait. Si, de plus, on veut ajouter des logs parlant (c’est à dire avec, au minimum, le temps de traitement d’un fichier et son nom), cela a tendance a rajouter du bruit au code. Sans oublier que lire un fichier est bien mais que, souvent, un traitement est effectué dessus…
Enfin, lors d’une forte volumétrie, une scalabilité horizontale peut être intéressante surtout dans le contexte actuel où la quantité d’information vient à exploser.
Cet article parlera donc de la problématique d’import de fichiers dans une application en s’appuyant sur des framework comme Spring Batch ou Spring Integration. Le mot d’ordre sera de le faire le plus simplement possible en s’appuyant au maximum sur ces framework.
Solution à base de batch
Ecrire un batch permettant de traiter des fichiers peut sembler simple mais lorsque le nombre de ces derniers vient à augmenter ou lorsque la taille des fichiers est volumineux, il arrive souvent que des bugs apparaissent. En outre, il convient alors de gérer manuellement les logs ainsi que la partie supervision.
Pour répondre à ce besoin, il est peut être avantageux d’utiliser Spring Batch (ou une autre implémentation de la JSR 352).
ndlr : je ne présenterai pas le fonctionnement de Spring Batch à base de Job et Step puisque cela se trouve très facilement dans les documents officiels, livres ou articles de blog et je mettrai plutôt l’accent sur la faisabilité de tel ou tel chose.

Spring Batch offre nativement la possibilité de traiter les fichiers par chunk via :
FlatFileItemReaderqui permet de lire un fichier plat ligne par ligne et où chaque ligne dispose de la même information (il est également possible de traiter des types de lignes différentes issues du même fichier avecPatternMatchingCompositeLineMapper).StaxEventItemReaderpour lire fichiers xml composés de format de fragments identiques :
avec :
<bean id="itemReader" class="org.springframework.batch.item.xml.StaxEventItemReader">
<property name="fragmentRootElementName" value="trade" />
<property name="resource" value="data/iosample/input/input.xml" />
<property name="unmarshaller" ref="tradeMarshaller" />
</bean>
<bean id="tradeMarshaller"
class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<util:map id="aliases">
<entry key="trade"
value="org.springframework.batch.sample.domain.Trade" />
<entry key="price" value="java.math.BigDecimal" />
<entry key="name" value="java.lang.String" />
</util:map>
</property>
</bean>
Généralement, il est nécessaire de préciser le nom du fichier à traiter mais il est également possible d’en traiter plusieurs de même type dans la même Step via la classe MultiResourceItemReader.
<bean id="multiResourceReader" class="org.springframework.batch.item.file.MultiResourceItemReader">
<property name="resources" value="classpath:data/input/file-*.txt" />
<property name="delegate" ref="flatFileItemReader" />
</bean>
Spring Batch supporte également la scalabilité horizontale en permettant de préciser un taskExecutor au niveau de la Step.
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>
Ainsi, on constate que Spring Batch offre nativement la possibilité de traiter des fichiers volumineux en les découpant par chunk.
De même, il offre nativement la possibilité de passer sur du traitement parallèle.
Concernant la partie supervision, vu que l’on est dans un environnement Spring, on bénéficie, bien sûr, de toute la partie JMX.
Pour la partie gestion des erreurs, Spring Batch permet de les gérer de manière très simple.
Cependant, on perd un grand intérêt si, par fichier, il n’y a qu’une seule donnée. En effet, le mécanisme de chunk devient alors inutile. Il reste cependant possible d’utiliser la scalabilité horizontale.
Concernant la partie log, j’avoue ne pas avoir creuser, je ne dirai donc rien sur ce point…
Solution à base d’EIP
Dans le cas où la volonté serait de traiter les fichiers au fil de l’eau, Spring Batch n’est pas la solution la plus adaptée…
Cependant, Spring Integration répond à ce besoin de manière très simple.
En effet, en utilisant un simple Service Activator (au sens EIP) de type inbound-channel-adapter, il devient alors possible de poller un répertoire et d’envoyer le contenu du fichier vers un filter (au sens EIP).
<file:inbound-channel-adapter id="fileAdapter" auto-startup="true" auto-create-directory="true"
filename-pattern="*.xml"
directory="file:/tmp"
scanner="recursiveScanner"
prevent-duplicates="true"
channel="inputChannel">
<int:poller fixed-delay="30000" max-messages-per-poll="500"/>
</file:inbound-channel-adapter>
<file:file-to-string-transformer charset="UTF-8" delete-files="true" input-channel="inputChannel"
output-channel="toLogger"/>
<int:logging-channel-adapter auto-startup="true" channel="toLogger" level="DEBUG" log-full-message="true"/>
<int:channel id="inputChannel"/>
<int:channel id="toLogger"/>
D’un point de vue scalabilité horizontale, il suffit de renseigner (tout comme pour Spring Batch) un taskExecutor au niveau du Channel et… c’est tout!
<task:executor id="someExecutor"
pool-size="20"
keep-alive="2400"/>
<int:channel id="toLogger">
<int:dispatcher task-executor="someExecutor"/>
</int:channel>
Enfin, disposer d’une supervision est des plus aisé puisqu’il suffit de rajouter l’élément message-history :
<int:message-history/>
L’ajout de cet élément indique à Spring Integration qui doit ajouter automatiquement dans le header du message le temps d’exécution de chaque Filter. Concernant le nom du fichier et son chemin, il se trouve renseigner automatiquement dans le header par l’adapter file:inbound-channel-adapter.
Coté gestion des erreurs, Spring Integration permet de les gérer très simplement sur le principe du canal d’erreur qui peut récupérer tous les messages en erreur.
Cependant, avec Spring Integration, si le fichier est volumineux, il n’est plus possible de le traiter en chunk et un risque de contention mémoire existe.
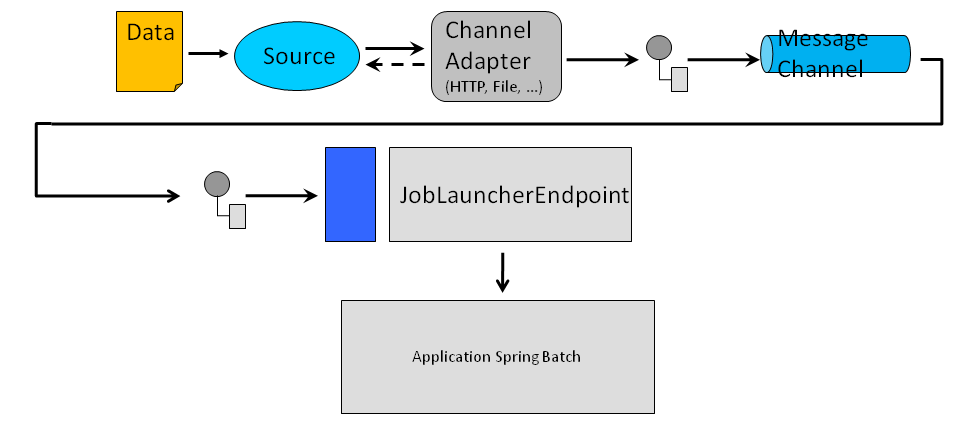
Solution à base d’EIP et de batch
On a vu dans les deux paragraphe précédent que Spring Integration était une très bonne solution pour traiter des fichiers au fil de l’eau alors que Spring Batch était plutôt orienté traitement par batch.
Cependant, il est très facile de composer les 2 modes. Cela permet, par exemple, de déclencher un traitement d’un fichier volumineux dès sa réception (via Spring Integration) et de bénéficier du mode chunk de Spring Batch pour le traitement.
Dans ce cas, bien sûr, il n’est pas question de faire de traitement sur le contenu du fichier dans la partie Spring Integration (seul l’objet File est transmis dans le corps du message) et c’est le jobs Spring Batch qui s’occupera du traitement à proprement parler.
Cela engendre peut être un overhead conséquent mais on est, au moins sûr, d’éviter le Out Of Memory dans le cas de fichiers volumineux. En outre, cela permet de bénéficier de la puissance des EIP (routage ou filtrage sur le nom du fichier par exemple) tant que le fichier n’a pas à être chargé.
Conclusion
On a vu dans cet article comment il pouvait être trivial de traiter l’import de fichiers sans avoir à gérer manuellement des pools de thread ou des logs d’audit.
Je ne suis pas rentré dans les détails mais mon objectif était surtout de montrer qu’en utilisant les bons outils/framework, il était possible de produire du code minimaliste et donc moins propice aux erreurs.
Pour avoir mis en oeuvre ces solutions, je peux vous assurer que le code écrit (ainsi que le temps passé) était minimaliste sinon nul (si on considère qu’écrire du xml n’est pas du code…). Bien sûr, je ne parle pas du code de traitement qui doit être écrit quoiqu’il arrive mais, encore une fois, le fait d’expédier la partie plomberie a permis de se concentrer sur le réel besoin métier.
Enfin, il est important de préciser que dans certains cas, une telle approche ne fonctionnera pas (si un fichier contient, par exemple, des dépendances à des données issues d’autres fichiers) et qu’il peut même être dangereux de vouloir absoluement utiliser ce type de framework au risque de leur faire faire des choses pour lesquelles ils ne sont pas prévus… Par exemple, il ne faut pas oublier que dans EIP, le I signifie Intégration!! Si le besoin est autre, il est fortement recommandé d’utiliser autre chose ou de le faire manuellement mais, par pitié, ne tordez pas le coup aux outils…! (si si, je l’ai vu… d’où mon désarroi…).
ndlr : bon, j’admets que la partie qui a dû être la plus longue a sûrement été le tuning du pool de thread afin de tirer le meilleur partie de la machine mais, même si cela avait été fait de manière programmatique, cela aurait été nécessaire…
ndlr : j’ai parlé, dans cet article, de Spring Integration pour la partie EIP mais il est tout aussi simple d’utiliser Apache Camel.
Pour aller plus loin…
- Spring Integration in Action de Mark Fisher, Jonas Partner, Marius Bogoevici et Iwein Fuld chez Manning
- Camel in Action de Claus Ibsen et Jonathan Anstey chez Manning
- Spring Batch in Action de Arnaud Cogoluegnes, Thierry Templier, Gary Gregory et Olivier Bazoud chez Manning
- Enterprise Integration Patterns de G. Hohpe et B. Woolf chez Addisson Wesley
- http://www.eaipatterns.com/
- http://projects.spring.io/spring-integration/
- http://projects.spring.io/spring-batch
- http://www.technologies-ebusiness.com/langages/spring-batch-spring-integration-une-usine-de-batchs-a-moindre-cout