
Cet article fait suite à mon article précédent afin de donner mon rapide retour d’expérience sur quelques écueils qui peuvent être commis lors de l’écriture d’un microBenchmark et dans lesquels je suis, bien sûr, tombé :(. Pour remettre dans le contexte, c’est l’écriture de ce benchmark qui a entrainé l’écriture de mon article précédent suite aux résultats que j’ai pu constater et pour lesquels j’ai eu l’aide de mes camarades.
Contexte
Un collègue me disait que le foreach était moins performant qu’une boucle for en raison du fait que l’invocation d’une opération supplémentaire (la méthode next()) rendait l’opération plus lente en raison de la pile de notre cher compteur ordinal (pour ceux qui ne se rappelleraient pas, je vous renvoie sur vos cours d’assembleur ;-) ), enfin que, du moins, en .Net ça marchait comme ça. Ma réponse : “ben j’en sais rien” puisque je ne savais pas quelles étaient les optimisations faites par le compilateur (ouais, je sais, super les sujets de conversation…).
Du coup, ni une, ni deux, j’ai ouvert mon IDE préféré et j’y ai jeté quelques lignes de code pour avoir ma réponse, et là… ce fut le drame… : des résultats bizarres sont apparus…
Ce petit article a donc pour objectif de vous fournir le résultat de ce qu’il faut faire et ne pas faire lors de l’écriture d’un microBenchmark mais également de fournir la réponse que tout le monde attend, à savoir : qui est réellement le plus fort entre le for et le foreach (ça peut éviter d’avoir à perdre 5 minutes de test…).
Bien sûr, n’étant pas expert dans ce domaine, il s’agit juste d’un retour d’expérience dont je vous laisse seul juge de la véracité… ;-)
Premier disclaimer : contrairement à ce que j’ai présenté dans mon post précédent, je n’effectuerai pas, ici, différents tirs sur différentes architectures d’ordinateurs, VM ou avec différentes options. En effet, ce qui m’intéresse dans cet article est d’entrevoir ce qui peut se passer dans la VM et comment cela peut impacter les performances d’un petit bout de code.
Deuxième disclaimer : lors de la procédure d’élagage, un coefficient de 0,5 sera utilisé afin de lisser au maximum mes résultats et cela, en raison de pics très importants observés (pics liés, comme nous le verrons par la suite soit, au warm-up de la JVM, soit au GC).
Procédure de test et analyse
Première tentative
Scénario
Ma première tentative de benchmark était la suivante :
- on instancie une liste d’un chaîne de caractère,
- on itère dessus sans rien faire,
- on regarde le temps passé.
Ce petit test sera exécuté une centaine de fois afin de pouvoir lisser le résultat.
Le code utilisé pour faire ce petit test est le suivant :
public class IterableBenchmark0 {
private final static int NB_ITEM = 100000;
private final static int NB_TEST = 100;
static List<String> list = new ArrayList<String>(NB_ITEM);
static {
for (int i = 0; i < NB_ITEM; i++) {
list.add(Integer.toString(i));
}
}
public static void main(String[] args) {
Long[] res = new Long[NB_TEST];
for (int j = 0; j < NB_TEST; j++) {
long startTime = System.nanoTime();
for (int i = 0; i < list.size(); i++) {
}
// for (String value : list) {
// }
// int i = 0;
// while (i < list.size()) {
// i++;
// }
res[j] = (System.nanoTime() - startTime);
}
long total = 0;
for (int j = 0; j < NB_TEST; j++) {
total += res[j];
System.out.println(res[j]);
}
System.out.println("sum : " + total);
System.out.println("moy : " + total / NB_TEST);
}
}
On y constate, bien sûr, que la récupération des métriques n’encadre que l’opération à tester mais, également, que l’instanciation et l’initialisation de l’ArrayList utilisé ici sont faites en dehors du test.
Résultats
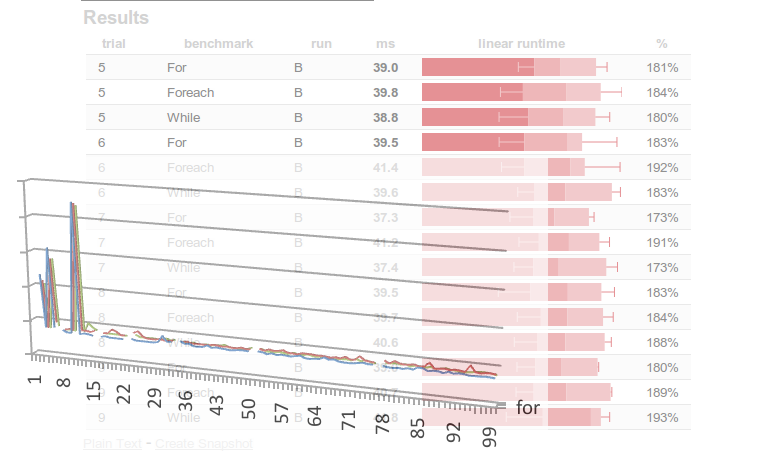
Suite à ce test, les résultats obtenus ont été les suivants :

Après élagage des résultats abérants (procédé commun à tous tes des charges), ces résultats peuvent être réduits aux résultats suivants (ici, k = 0,5) :
Analyse
Les résultats précédents montrent clairement une différence entre les tirs avec et sans élagages (normal me direz-vous). Cependant, elles apparaissent principalement sur les deux premières itérations de notre boucle chargée d’itérer notre List.
En outre, après élagage, on constate, malgré tout, qu’une nette différence persiste entre les boucles for et while et notre foreach.
A titre informatif, c’est à ce moment là que j’ai dû appeler mes amis (ça ne vous rappelle pas quelque chose…?) pour obtenir une analyse plus précise des résultats que je ne comprenais pas… :( Du coup (et là, je ne vais pas me fouler ;-) ), je vous cite les réponses des différents intéressés (et oui, il est possible d’avoir plusieurs amis… (si cela vous amuse, je vous laisse deviner qui a dit quoi) que je remercie encore une fois ;-) :
- première réponse :
Ces résultats sont parfaitement logiques. Pour for et while, la VM s’aperçoit au bout de quelques itérations que la boucle est inutile.
- on connaît le nombre d’itérations sans avoir besoin d’itérer réellement sur la liste (list.size() est fixe) ;
- la boucle n’a aucun “side-effect” en-dehors. Du coup, la boucle entière est éliminée, d’où les temps nuls. Pour for-each, c’est plus compliqué :
- La notation syntaxique “for-each” est compilée sous la forme d’un parcours d’itérateur : for (Iterator it=list.iterator(); it.hasNext; ) { … }
Du coup, impossible de connaître le nombre d’itérations à l’avance : la JVM est obligée de tout parcourir
- En plus, pour éviter les modifications concurrentes de la collection (celles qui lancent le fameux ConcurrentModificationException), la méthode next() effectue des vérifications, qui prennent du temps.
Bref, dans ce cas, for-each est moins performant, ou du moins, nettement moins optimisable, que “for” ou “while”
Si tu veux un test plus représentatif des performances réelles, moins sujettes à des optimisations agressives, il faut que les boucles aient un “side-effect” (par exemple, ajouter chaque élément parcouru dans une seconde liste, située en-dehors de la boucle).
- deuxième réponse :
(…) la Hotspot utilise la zone “code cache” pour cacher des informations à la volée et compiler du code plus optimisé grâce à JIT en fonction des hotspots détectés. Je viens de retrouver un post sur le blog de Sun qui confirme ce mécanisme. Il montre un exemple sur l’optimisation d’une boucle while: http://blogs.sun.com/ahe/entry/hotspot_and_other_compilers
- troisième réponse :
Alors tout d’abord, je pense que comparer le for et le foreach n’a pas de sens en soi… En effet, il ne faut pas oublier que quand tu écrit ton code Java, celui-ci est compilé en .class (bytecode).
Ces .class sont alors interprétés ou compilés à la volées (par le compilateur Just In Time).
De plus, comme tout micro-benchmark Java, il faut se méfier des résultats. Tout simplement, le comportement de la JVM (Hotspot) change du tout au tout en fonction des paramètres VM (-server et -client, les cycles d’optimisation…)
Ensuite, si ton code est fort utilisé, il sera automatiquement “inliné” par le JIT…
Je pense que les conclusions à tirer sont claires… le code testé est erroné : mon Compilateur Planning m’a inliné le code à tester et le fait que les deux premières itérations soit si élevées par rapport aux autres résultats est lié au warm-up de ma JVM.
Je pense que les conclusions à tirer sont claires… le code testé est erroné : mon Compilateur Planning m’a inliné le code à tester et le fait que les deux premières itérations soit si élevées par rapport aux autres résultats est lié au warm-up de ma JVM.
Deuxième tentative
Scénario
Du coup, suite à ma première tentative de benchmark infructueuse, deuxième essai en apprenant de mes erreurs… :
- on instancie une liste d’un chaîne de caractère,
- on itère dessus en ajoutant un effet de bord afin d’empêcher mon Compilateur Planning de m’inliner mon code,
- on regarde le temps passé.
Comme précédemment, ce petit test sera exécuté une centaine de fois afin de pouvoir lisser le résultat.
Le code utilisé pour faire ce petit test est le suivant :
public class IterableBenchmark1 {
private final static int NB_ITEM = 100000;
private final static int NB_TEST = 100;
static List<String> list = new ArrayList<String>(NB_ITEM);
static {
for (int i = 0; i < NB_ITEM; i++) {
list.add(Integer.toString(i));
}
}
static StringBuilder sideEffect = new StringBuilder();
public static void main(String[] args) {
Long[] res = new Long[NB_TEST];
for (int j = 0; j < NB_TEST; j++) {
long startTime = System.nanoTime();
for (int i = 0; i < list.size(); i++) {
sideEffect.append(list.get(i));
}
// for (String value : list) {
// sideEffect.append(value);
// }
// int i = 0;
// while (i < list.size()) {
// sideEffect.append(list.get(i));
// i++;
// }
res[j] = (System.nanoTime() - startTime);
}
long total = 0;
for (int j = 0; j < NB_TEST; j++) {
total += res[j];
System.out.println(res[j]);
}
System.out.println("sum : " + total);
System.out.println("moy : " + total / NB_TEST);
}
}
Résultats
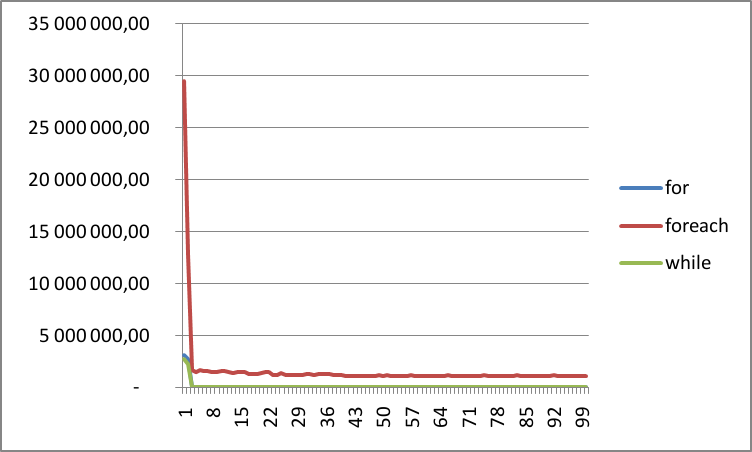
Suite à ce test, les résultats obtenus ont été les suivants :


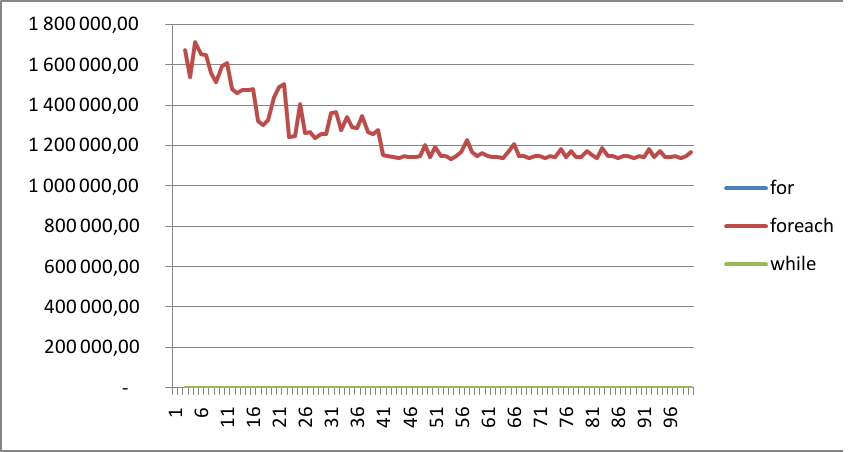
Après élagage des résultats aberrants (procédé commun à tous tests des charges), ces résultats peuvent être réduits aux résultats suivants (ici, k = 0,5) :

A noter que ce graphique n’est toujours isssu que d’un seul tir…
Analyse
Les résultats semblent enfin cohérents! ouf…!
En effet, on constate que, mis à part les GC, et le warm-up de ma VM, mon Compilateur Planning n’a pas réussi à inliner mon code et me fournit, du coup, le résultat attendu.
Après un coup d’élagage me permettant de me débarrasser de mes pics liés au GC, mes courbes sont lissées et se chevauchent même.
Enfin, j’ai ma réponse (mais je garde ça pour plus tard même si je suppose que, du coup, vous connaissez le fin mot de l’histoire!… mais attendez, ne partez pas… la suite est intéressante également ;-))
Troisième tentative
Scénario
Bon, il est vrai, j’ai obtenu mon résultat sur ma deuxième tentative.
Cependant, pendant la présentation de Joshua Bloch (cf. post précédent), un point m’a particulièrement intéressé : le framework Caliper.
En effet, ce framework semble être fait pour répondre aux problématiques des microBenchmark.
Du coup, je vais, ici, montrer comment je l’ai utilisé ainsi que les résultats qu’il m’a fourni.
Deux raisons à cela :
- valider mes résultats précédents afin de vérifier que je n’ai rien laissé passer…
- m’amuser un peu… ;-)
Disclaimer : cette partie n’abordera ni comment installer, ni comment utiliser Caliper. Elle est juste fournie à titre indicatif.
Le code utilisé pour faire cette troisième tentative est le suivant :
public class IterableBenchmark2 extends SimpleBenchmark {
private final static int NB_ITEM = 100000;
List list = new ArrayList(NB_ITEM);
StringBuilder sideEffect = null;
@Override
protected void setUp() throws Exception {
for (int i = 0; i < NB_ITEM; i++) {
list.add(Integer.toString(i));
}
sideEffect = new StringBuilder();
}
public StringBuilder timeFor(int reps) {
for (int i = 0; i < reps; ++i) {
for (int j = 0; j < list.size(); j++) {
sideEffect.append(list.get(j));
}
}
return sideEffect;
}
public StringBuilder timeForeach(int reps) {
for (int i = 0; i < reps; ++i) {
for (String value : list) {
sideEffect.append(value);
}
}
return sideEffect;
}
public StringBuilder timeWhile(int reps) {
for (int i = 0; i < reps; ++i) {
int j = 0;
while (j < list.size()) {
sideEffect.append(list.get(j));
j++;
}
}
return sideEffect;
}
public static void main(String[] args) throws Exception {
Runner.main(IterableBenchmark3.class, args);
}
}
On remarque ici, que, plutôt que d’exécuter via un script extérieur mon tir, j’ai préféré le faire en invoquant directement le main().
Résultats
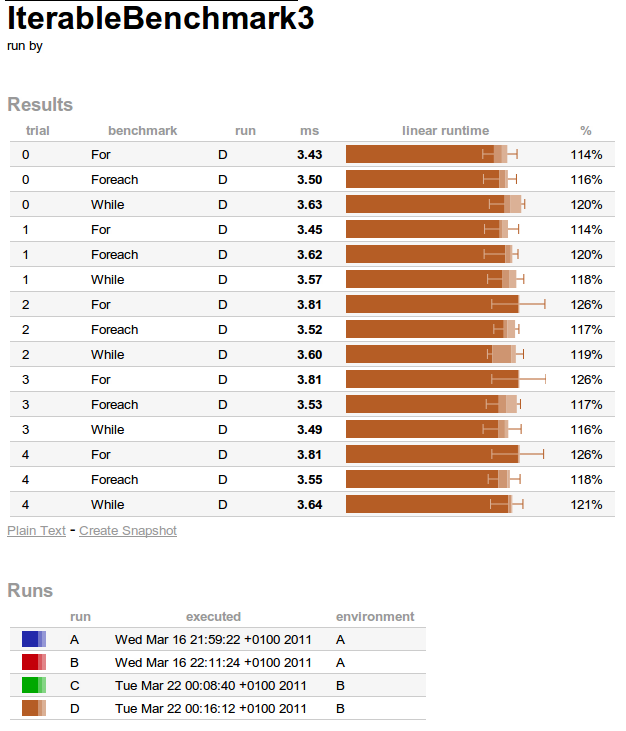
Suite à ce test, les résultats obtenus ont été les suivants :
0% Scenario{vm=java, trial=0, benchmark=For} 3535251,80 ns; σ=197827,29 ns @ 10 trials
33% Scenario{vm=java, trial=0, benchmark=Foreach} 3676070,55 ns; σ=190018,30 ns @ 10 trials
67% Scenario{vm=java, trial=0, benchmark=While} 3508898,75 ns; σ=222565,30 ns @ 10 trials
benchmark ms linear runtime
For 3,54 ============================
Foreach 3,68 ==============================
While 3,51 ============================
vm: java
trial: 0
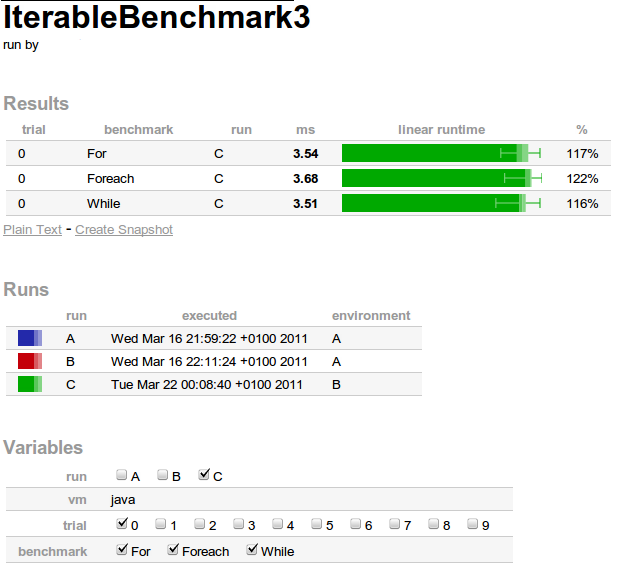
Ces résultats sont donnés avec une seul tir.
Pour montrer comme il est aisé d’effectuer plusieurs tirs avec Caliper (tir qui lance à chaque fois une nouvelle JVM dans un process - process au sens UNIX du terme - différent), modifions juste notre méthode main() pour y passer d’autres options :
public static void main(String[] args) throws Exception {
Runner.main(IterableBenchmark3.class, new String[] { "--trials", "5"});
}
Ce qui donne le résultat suivant :
0% Scenario{vm=java, trial=0, benchmark=For} 3425915,23 ns; σ=207711,73 ns @ 10 trials
7% Scenario{vm=java, trial=1, benchmark=For} 3453313,87 ns; σ=193613,25 ns @ 10 trials
13% Scenario{vm=java, trial=2, benchmark=For} 3807062,28 ns; σ=278917,43 ns @ 10 trials
20% Scenario{vm=java, trial=3, benchmark=For} 3807244,53 ns; σ=283377,19 ns @ 10 trials
27% Scenario{vm=java, trial=4, benchmark=For} 3808771,58 ns; σ=270090,07 ns @ 10 trials
33% Scenario{vm=java, trial=0, benchmark=Foreach} 3504679,81 ns; σ=190093,88 ns @ 10 trials
40% Scenario{vm=java, trial=1, benchmark=Foreach} 3620052,15 ns; σ=216116,18 ns @ 10 trials
47% Scenario{vm=java, trial=2, benchmark=Foreach} 3519711,06 ns; σ=173384,58 ns @ 10 trials
53% Scenario{vm=java, trial=3, benchmark=Foreach} 3527981,05 ns; σ=232274,54 ns @ 10 trials
60% Scenario{vm=java, trial=4, benchmark=Foreach} 3549837,79 ns; σ=196295,32 ns @ 10 trials
67% Scenario{vm=java, trial=0, benchmark=While} 3628542,80 ns; σ=223275,59 ns @ 10 trials
73% Scenario{vm=java, trial=1, benchmark=While} 3569981,43 ns; σ=225773,17 ns @ 10 trials
80% Scenario{vm=java, trial=2, benchmark=While} 3596601,06 ns; σ=266773,47 ns @ 10 trials
87% Scenario{vm=java, trial=3, benchmark=While} 3493799,14 ns; σ=220276,60 ns @ 10 trials
93% Scenario{vm=java, trial=4, benchmark=While} 3642079,85 ns; σ=185312,29 ns @ 10 trials
benchmark trial ms linear runtime
For 0 3,43 ==========================
For 1 3,45 ===========================
For 2 3,81 =============================
For 3 3,81 =============================
For 4 3,81 ==============================
Foreach 0 3,50 ===========================
Foreach 1 3,62 ============================
Foreach 2 3,52 ===========================
Foreach 3 3,53 ===========================
Foreach 4 3,55 ===========================
While 0 3,63 ============================
While 1 3,57 ============================
While 2 3,60 ============================
While 3 3,49 ===========================
While 4 3,64 ============================
vm: java

Analyse
On constate ici que les résultats obtenus avec Caliper sont cohérents avec ceux obtenus précédemment (ie. les résultats sont similaires quelque soit la méthode d’itération), même si on remarque une légère différence due au bruit ajouté par l’utilisation du framework, bruit qui ne doit pas être pris en compte puisque si un tel framework venait à être utilisé, tous les résultats analysés seraient, évidemment, issus de l’utilisation de Caliper. En outre, n’oublions pas qu’il faut raisonner en terme de statistique et non en terme de chiffre pur…
Quatrième tentative… juste pour le fun
Scénario
Cette avant dernière tentative est juste faite pour le fun pour montrer le comportement de Caliper avec un microBenchmark douteux… ie. notre premier test ;-).
Aussi, reprenons notre troisième tentative et supprimons les effets de bord :
public class IterableBenchmark3 extends SimpleBenchmark {
private final static int NB_ITEM = 100000;
List list = new ArrayList(NB_ITEM);
@Override
protected void setUp() throws Exception {
for (int i = 0; i < NB_ITEM; i++) {
list.add(Integer.toString(i));
}
}
public void timeFor(int reps) {
for (int i = 0; i < reps; ++i) {
for (int j = 0; j < list.size(); j++) {
}
}
}
public void timeForeach(int reps) {
for (int i = 0; i < reps; ++i) {
for (String value : list) {
}
}
}
public void timeWhile(int reps) {
for (int i = 0; i < reps; ++i) {
int j = 0;
while (j < list.size()) {
j++;
}
}
}
public static void main(String[] args) throws Exception {
Runner.main(IterableBenchmark3.class, args);
}
}
Résultats
Suite à ce test, les résultats obtenus ont été les suivants :
0% Scenario{vm=java, trial=0, benchmark=For} Failed to execute java -cp /home/khanh/eclipse-workspace/benchmark/target/classes:/home/khanh/eclipse-workspace/caliper-read-only/caliper/target/classes:/home/khanh/.m2/repository/com/google/code/gson/gson/1.7-SNAPSHOT/gson-1.7-SNAPSHOT.jar:/home/khanh/.m2/repository/com/google/guava/guava/r07/guava-r07.jar:/home/khanh/.m2/repository/com/google/code/java-allocation-instrumenter/java-allocation-instrumenter/2.0/java-allocation-instrumenter-2.0.jar com.google.caliper.InProcessRunner --warmupMillis 3000 --runMillis 1000 --measurementType TIME --marker //ZxJ/ -Dbenchmark=For fr.soat.blog.benchmark.IterableBenchmark3
starting Scenario{vm=java, trial=0, benchmark=For}
[caliper] [starting warmup]
[caliper] [starting measured section]
Error: Doing 2x as much work didn't take 2x as much time! Is the JIT optimizing away the body of your benchmark?
Analyse
La bonne surprise est que Caliper nous indique clairement que JIT a optimisé notre code et que, donc, notre microBenchmark est erroné!
A voir s’il se comporte ainsi avec tous les microBenchmark erronés…
Cinquième tentative… allez, une dernière pour la route
Scénario
Cette dernière tentative permet de voir ce qui se passerait si on désactivait JIT via l’option -Xint.
Pour rappel, l’option Xint permet de :
Operate in interpreted-only mode. Compilation to native code is disabled, and all bytecodes are executed by the interpreter. The performance benefits offered by the Java HotSpot Client VM’s adaptive compiler will not be present in this mode.
Le code utilisé est celui de notre première tentative.
Résultats
Suite à ce test, les résultats obtenus ont été les suivants :

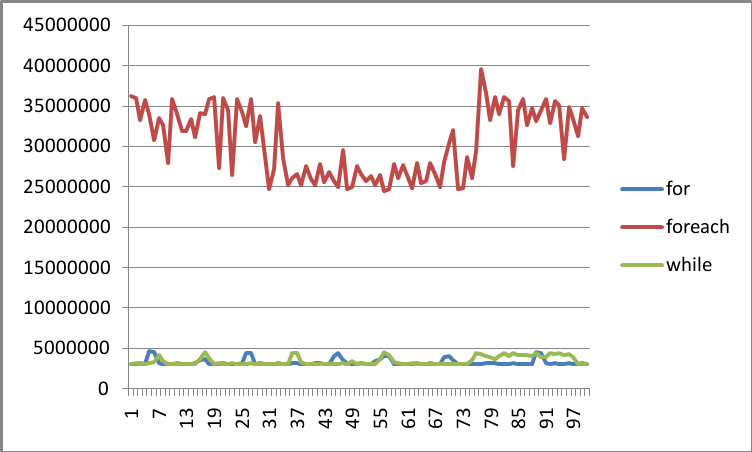
Après élagage des résultats aberrants (procédé commun à tous tes des charges), ces résultats peuvent être réduits aux résultats suivants (k = 1) :
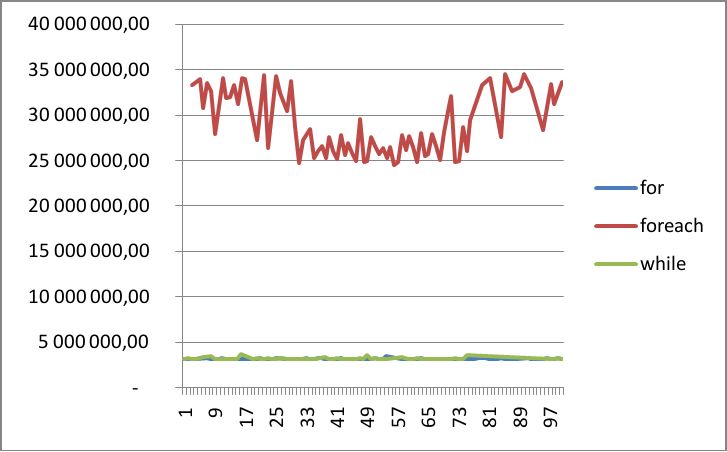
A noter que ce graphique n’est toujours issu que d’un seul tir…
Analyse
Bien sûr, ces résultats ne sont pas du tout représentatifs puisque le byte code est seulement interprété par la JVM et que cela ne représente pas la réalité. Cette dernière tentative n’est présentée qu’à titre indicatif afin de constater les différences qu’il peut y avoir entre le code que l’on écrit (ou compilé) et le code qui est réellement exécuté.
Conclusion
Voilà, j’arrive à la fin de mes conclusions que je vous cite en vrac ;-) :
- faire un microBenchmark est difficile et cet article ne montre qu’une ébauche des difficultés que cela peut poser,
- il est plus simple d’utiliser un outil qui sait bien faire son travail,
- il ne faut pas toujours se fier à ce que l’on peut constater : le risque que le cas observé ne soit pas représentatif de la réalité est élevé, d* e manière générale, on peut dire qu’il y a match nul entre le for et le foreach (en tout cas, dans notre cas de figure!).
Bon, un dernier mot : cet article n’apportera rien aux personnes déjà sensibilisées à ce type de problématiques et ce qu’on peut retenir est qu’il ne faut pas tenter d’optimiser inutilement son code (cf. article précédent). Je trouvais juste les résultats intéressants à montrer ;-)
Ah oui, encore une chose, pour information, mon ordinateur possède les caractéristiques suivantes :
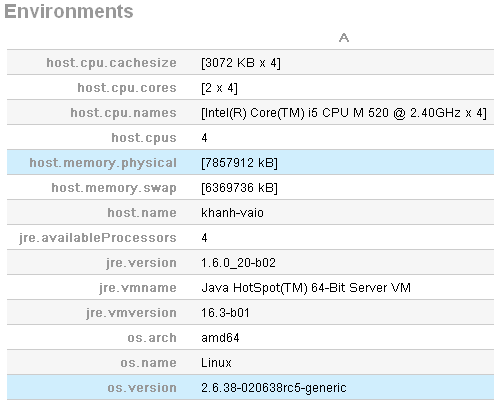
Remerciements
Par ordre alphabétique :
- Zouheir Cadi (@ZouheirCadi),
- Olivier Croisier (@OlivierCroisier),
- Arnault Jeanson (@ArnaultJeanson),
- Séven Lemesle (@slemesle)
- et François Ostyn (@ostynf)
Pour aller plus loin…
- Présentation de Joshua Blosh sur Parleys : http://www.parleys.com/#sl=0&st=5&id=2103
- Site du framework Caliper : http://code.google.com/p/caliper/
- Présentation de Cliff Click : http://www.azulsystems.com/events/javaone_2009/session/2009_J1_Benchmark.pdf
- Page Wiki de Sun sur le microBenchmark : http://wikis.sun.com/display/HotSpotInternals/MicroBenchmarks
- Page de google Android sur la gestion des perfomances d’Android : http://developer.android.com/guide/practices/design/performance.html