
 Cela fait un moment que je n’ai rien écrit… Cependant, un sujet me taraude depuis un moment… et il s’agit de la gestion des logs dans les applications.
Cela fait un moment que je n’ai rien écrit… Cependant, un sujet me taraude depuis un moment… et il s’agit de la gestion des logs dans les applications.
J’ai déjà pesté dans des articles précédents sur le fait qu’une application devait toujours être monitorée et supervisée mais, en plus de cela, le comportement d’une application doit également être traçable.
Le sujet n’est pas ce qu’on peut dire le plus sexy du monde mais j’ai souvent constaté que ce dernier était souvent assez mal maitrisé. Donc désolé si j’enfonce des portes ouvertes mais bref…
Dans une mouvance où on parle de plus en plus de BigData, l’un de ses enjeux est la récupération du maximum d’informations afin de pouvoir en retirer de la valeur. Parmi ces informations, le log en fait parti. En effet, il peut être très riche en indicateur et peut apporter une valeur inespérée pour le métier (actions utilisateurs, …) ou pour connaitre la santé du système (KPI, …).
Bien sûr, la notion de gestion et de traitement de logs n’est pas venu avec le BigData mais existe depuis le début de l’informatique. Cependant, l’arrivé d’architecture distribuée (ou cloud) a entrainé d’autres problématiques comme l’aggrégation des logs (avec les problématiques classiques d’ordonnancement et de NTP par exemple).
Aussi, dans cet article, je reviendrai sur certains points qui me semblent primordiaux (et qui sont souvent oubliés) et pour cela, j’aborderai différents notions :
- Définition des différents type de log
- Limitation des approches naîve
- Préconisation
A noter que je ne parlerai pas ou peu technique et que je n’aborderai pas comment il est possible de transmettre les logs ou de les agréger.
Définition des différents type de logs
Type de logs
Il existe différents types de logs dans un système. De manière classique, on peut les classifier de la manière suivante :
- Operation log : il s’agit de logs à destination des équipes d’exploitation. Ces logs sont plus orientés supervision et sont souvent intégrés à un système d’alerting.
- Chrono log : il s’agit de logs qui renseignent sur le temps d’exécution de différents types d’action comme le temps d’exécution d’une requête. Ces logs sont plus orientés supervision et sont souvent intégrée à un système d’alerting.
- Audit log (aussi appelé journaux) : il s’agit de logs métiers qui permettent, par exemple, de suivre le parcours/action des utilisateurs. Ces logs peuvent être utilisés à des fins de journalisation.
- Diagnostic log : il s’agit de logs plus techniques qui peuvent contenir les erreurs techniques ou des informations de débuggage. Ces logs sont souvent utilisés à des fins de troubleshooting.
 |
Pour le cas des Chrono log, il existe des librairies qui sont spécialisées dans la remontée de métriques temporelles.
Elles proposent souvent des métriques agrégées tel que :
L’AOP (Aspect Oriented Programming) est également un très bon candidat pour répondre au besoin des Chrono log. |
Niveau de logs
Communément, on trouve différents niveaux de log :
- TRACE : il s’agit du niveau de logs le plus fin et est souvent à destination des équipes de développement afin de leur fournir des informations complémentaires. Ces logs n’ont pas vocation à être sauvegardées.
- DEBUG : il s’agit d’informations détaillées utilisées pour le suivi de l’exécution du programme afin de permettre la correction d’anomalie.
- INFO : il s’agit d’informations plus orientées métier c’est-à-dire qu’elles ont pour vocation de fournir le contexte d’exécution plus applicative.
- WARN : il s’agit d’informations ayant pour vocation d’alerter d’une situation d’exécution non idéale mais non critique pour l’application. Il peut s’agir, par exemple, d’informer qu’une propriété de configuration n’a pas été renseignée et que sa valeur par défaut est utilisée.
- ERROR : il s’agit d’informations permettant d’indiquer une situation d’erreur ou inattendue, qui n’entraine pas forcément une situation de blocage mais qui est anormal d’un point de vue technique ou fonctionnel (manque d’informations obligatoires par exemple).
- FATAL : il s’agit d’informations indiquant une erreur critique qui entraîne un blocage voire un arrêt du système (erreur de connexion à un système extérieur par exemple).
Certaines librairies peuvent disposer d’autres niveaux de logs comme c’est le cas de PSR-3 mais disposer de trop de niveaux de logs peut rendre difficile l’utilisation de ces librairies.
Limitation des approches classiques
Dans la plupart des cas, malheureusement, les logs ne sont pas structurés et c’est là où le bas blesse… En effet, une information non structurée est souvent inexploitable mis à part si le besoin est de faire l’équivalent d’un gros grep dessus.
Bien sûr, avec des solutions comme Hadoop qui sont schema on read et non schema on write, il est possible de repousser le problème en stockant tout brutalement sur HDFS. Cependant, afin de pouvoir exploiter l’information contenue dans le log, il est nécessaire d’en connaitre sa structure (utilisation de Hive pour une remonté dans une solution de BI par exemple). Alors, oui, il est possible de faire tourner des gros batch pour transformer la donnée (que ce soit avec avec des solutions comme Pig, Spark ou autre) ou de le faire avec une solution de type streaming (Logstash, Flume, Fluentd, …). Pourtant, même pour faire cela, encore faut-il savoir ce qu’on transforme.
En outre, souvent, pour passer d’un log non structuré à un log structuré, mis à part l’utilisation une grosse regex, il n’existe pas des masses de solutions. Et même dans ce cas, sauf si on est capable d’écrire une regex qui sait traiter tous les cas (ce dont je doute), cela est couteux en ressource machine et ces processus doit également être monitorés, scalable, haute dispo et tout ce qui va avec au risque de perdre de l’information… (en outre, il est alors nécessaire d’architecturer ce type de solution pour savoir les solutions à utiliser ainsi que les impacts qu’il peut y avoir sur les différents serveurs).
Préconisation
Suite aux constats ci-dessus, mon avis est qu’il faut formaliser ce qu’est un log afin de le rendre exploitable.
On peut déjà constaté qu’il est possible de classifier les informations d’un log en 2 catégories :
- les informations communes à tous les logs
- les informations spécifiques au log (raison de l’anomalie, action réalisée, …)
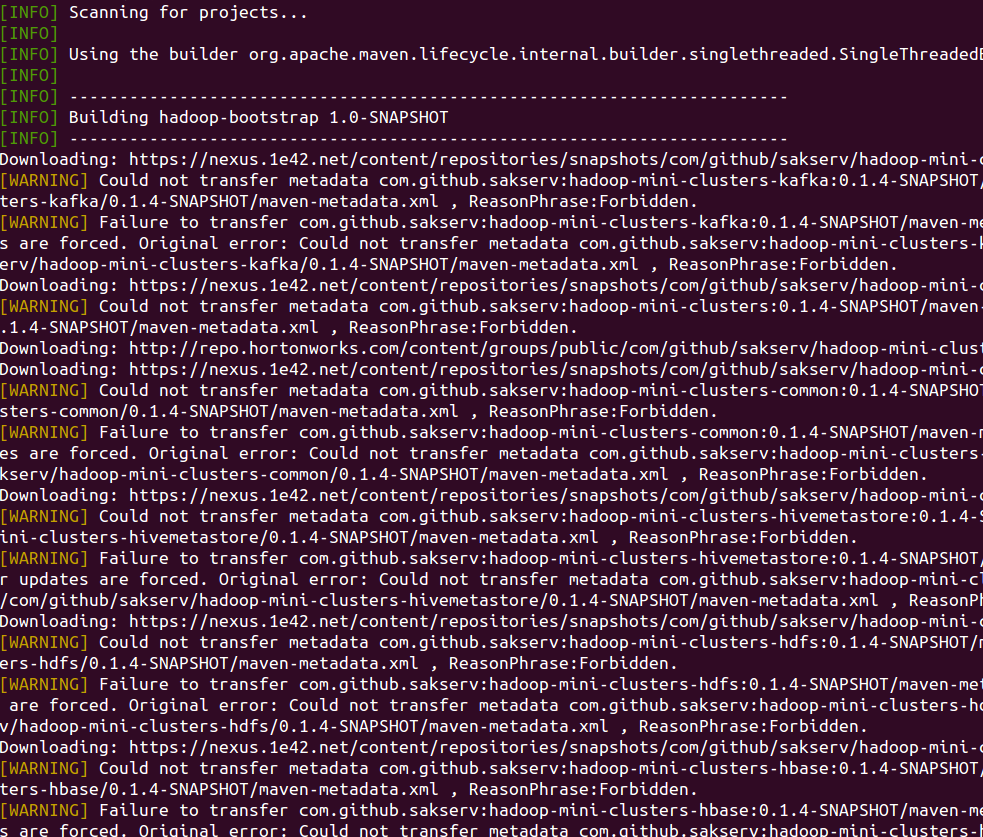
Ainsi, il est possible de formaliser un log de la manière suivante :
- d’un en-tête (header)
- et d’un corps (body).
Header
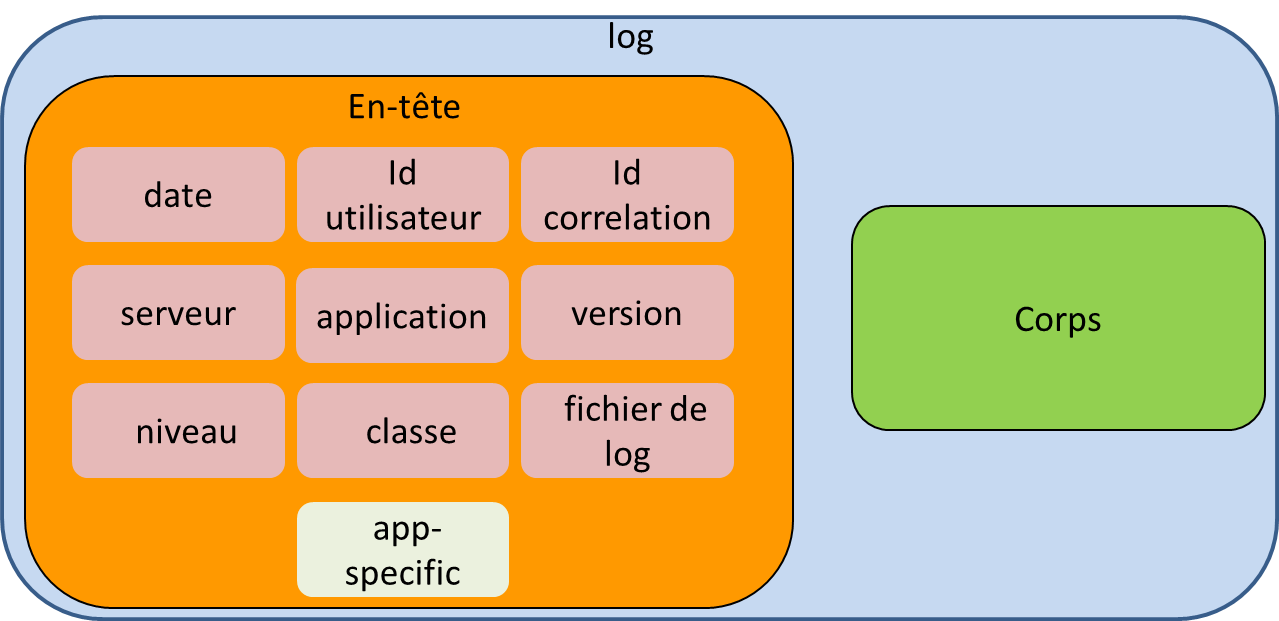
Quel que soit le type de log, il convient de pouvoir re-contextualiser les conditions d’exécution. Pour ce faire, il est possible d’avoir :
- une date,
- l’utilisateur (il peut s’agir de l’identifiant de l’utilisateur qui est commun à tous les composants de l’application ou du propriétaire de l’opération dans le cas d’un batch par exemple),
- un identifiant de corrélation permettant de suivre de bout en bout les actions (il peut s’agir par exemple, de l’identifiant de session web),
- le nom du serveur,
- le type de l’application (nom du portail ou composant backoffice),
- la version de l’applicatif ou du log,
- le niveau du log,
- le contexte (il peut s’agir d’un contexte d’environnement ou d’informations comme le user-agent),
- la classe ou la méthode où se trouve l’instruction qui a produit le log (classe au format FQN (Fully Qualified Name) par exemple),
- le nom du fichier d’où est issu le log si celui-ci a été écrit sur disque.
|
Disposer de la version du log peut être importante (si ce n'est primordiale) si de nouveaux champs venaient à être ajoutés (principalement dans l’en-tête). Cela peut impacter la façon d’exploiter l’information et entrainer une perte de cette dernière. Aussi, le log doit être vu comme un objet pivot et doit donc être versionné avec, si possible, un schéma bien défini. |
|
Certaines de ces informations sont, souvent, automatiquement renseignées par des librairies de log utilisées dans les différents écosystèmes. Aussi, généralement, les informations suivantes ne sont pas à renseigner :
|
| Certains autres composants peuvent renseigner des informations comme le nom du serveur. C’est, par exemple, le cas de Logstash ou Syslog. |
| Il existe des mécanismes pour attacher des informations clés qui doivent toujours être présentes dans le log comme les identifiants de l’utilisateur ou l’identifiant de sa session http. C’est le cas du MDC (Mapper Diagnostic Context) qui permet de véhiculer, dans le thread courant, un certain nombre d’informations qui peuvent être jugés utiles au log. Aussi à chaque appel de ce log, il disposera de ces informations. |
| Il est à noter que pour qu’une information (comme par exemple l’utilisateur) soit commune dans tous les logs émis par les composants de l’application, il faut qu’elle soit transmise dans les appels (en-tête de message SOAP, …). |
|
Ecrire les logs dans un fichier permet de rendre le traitement et la consommation des logs agnostique d’une technologie. En outre, cela permet de fournir un buffer et de rendre asynchrone tout traitement devant être effectué dessus. Une autre solution consiste à utiliser un broker de message type JMS, RabbitMQ ou Kafka mais cela peut introduire un composant tierce et peut lié le traitement des logs à une technologie supplémentaire. |
Body
Le corps du log est laissé à la discrétion de l’application qui doit fournir les informations qu’elle juge utile.
| Le log ne doit pas être source d’anomalie ni d’effet de bord |
|---|
| Il convient de se prémunir qu’un log ne doit pas être source d’erreur lors de la récupération des informations à y mettre. De la même manière, il ne doit pas engendrer un overhead lié à l’exécution d’une opération couteuse. |
Conclustion
Dans cet article, je n’ai fait qu’enfoncer des portes ouvertes et je suis parti du postulat que tous les types de logs (la dénomination log est discutable mais bon…) était des logs au sens classique du terme.
Il est bien sûr possible d’utiliser des solutions autres (par exemple, en remontant directement certains types dans des solutions spécifiques comme une base de données).
Malheureusement, souvent, la différentiation des types de logs n’existe pas et, il peut être plus simple, de tout considérer comme des types de logs différents (de toute façon, toute information fournit par l’application est importante donc autant les traiter de la même manière… c’est juste une question de référentiel… ;) )