
A l’origine, une des principales raisons à la mise en place d’un serveur d’intégration continue était l’automatisation des processus qui, fait manuellement, étaient souvent consommateur de temps et générateur d’erreurs humaines. Petit à petit, ce dernier s’est imposé comme l’orchestrateur de tous les processus et est devenu un des points central de l’usine de développement. En effet, en plus de ses capacités à compiler, packager, faire passer les tests unitaires, d’intégration et d’acceptance, il est souvent utilisé pour livrer mais également pour effectuer des tests de non régression.
Parmi ces tests de non regression, il est possible d’y inclure (en plus des classiques tests unitaires, d’intégration et d’acceptances) les tests de performances (JMeter, Gatling, Clif) et la remontée de métriques de qualité de code (PMD/CPD, Findbugs, Checkstyle, ou plus simplement Sonar).
Bien évidemment, récupérer des métriques sans les consolider ni les comparer avec l’historique est totalement inutile car cela n’offrirait aucune visibilité sur l’amélioration ou la dégradation du produit.
Ce petit laïus semble trivial pour ceux qui font du Java (enfin je l’espère… ;-) ). Cependant il l’est un peu moins dans le monde pur web (ie. lorsque l’on veut tester une couche pur front). Bien sûr, il y a Selenium & co mais cela ne permet de ne tester que le fonctionnel. En outre, en cherchant dans la littérature (pour rappel, je ne suis pas développeur front), on peut constater que, souvent, les outils utilisés pour obtenir des métriques sur la qualité de rendu d’une page ou le temps de chargement de ses différents composants sont souvent intégrés au navigateur du développeur et que, souvent, il est nécessaire de se faire des nœuds au cerveau pour les intégrer aux usines logicielles telles que celles dont l’écosystème Java a l’habitude.
Vous l’aurez compris, cet article a donc pour objectif de montrer comment il est possible d’intégrer tout ce beau monde…
Il se limitera cependant à la récupération de métriques sur la qualité de rendu d’une page ainsi qu’à son temps de chargement.
Dans un premier temps, cet article présentera donc comment il est possible de récupérer des métriques type YSlow ou Pagespeed (ie. une note globale sur la page) puis, dans un second temps, comment il est possible de récupérer des métriques sur le temps de chargement des pages. Enfin, pour faire le liant avec mes articles précédent, on verra comment il est possible de remonter et historiser ces métriques au travers un test d’acceptance.
Evidemment, l’objectif n’étant pas d’obtenir ces métriques de manière “one shot”, une attention particulière sera portée sur l’intégration de ces outils à une usine logicielle et à leurs capacités à fournir une évolution dans le temps.
HTML et ses bonnes pratiques
Contexte
Parmi les outils courants pour récupérer une évaluation d’une page HTML au sein d’un navigateur, il existe YSlow et Pagespeed. Ces deux outils fournissent un ensemble de notes qui permettent de qualifier les bonnes pratiques tels que la minification des fichiers Javascript.
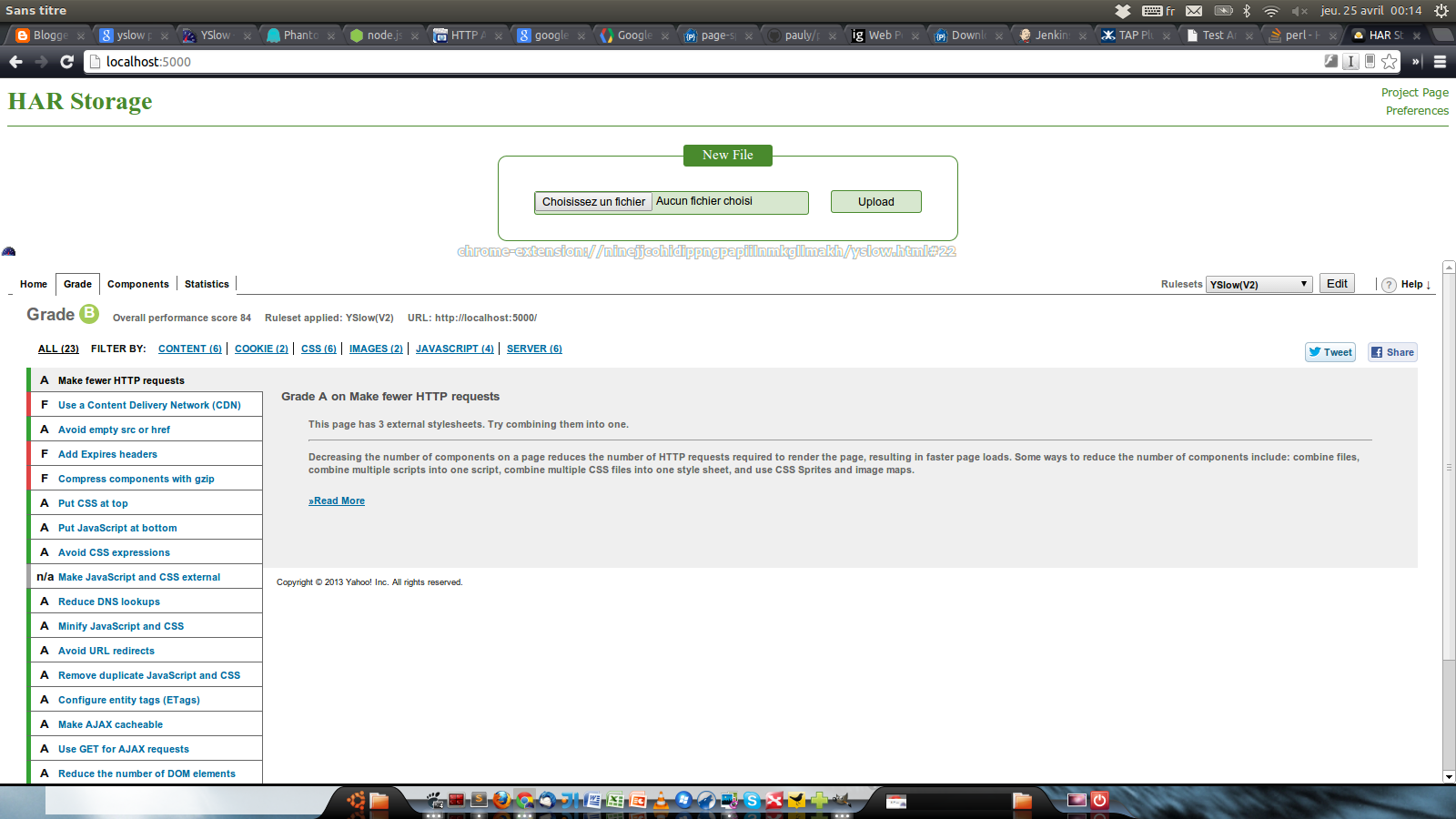
Bien sûr, le fait d’utiliser un plugin de navigateur n’est pas ce qu’il y a de plus industrialisable. Le besoin peut être décomposé en deux étapes :
- la récupération des métriques,
- la présentation de ces métriques dans un dashboard afin qu’elles soient lisibles et qu’il soit possible de voir leur évolution dans le temps.
Solution et mise en oeuvre
Comme dit dans le paragraphe précédent, il convient au préalable de générer les métriques.
Du coté de YSlow, cela est facilement faisable en s’appuyant sur phantomjs.
Pour ce faire, il suffit de récupérer et d’installer le binaire de phantomjs. Il reste ensuite à récupérer le script yslow.js puis d’exécuter la commande suivante :
/opt/phantomjs/bin/phantomjs yslow.js <url page>
Il est également possible de s’appuyer sur nodejs mais l’opération devient alors un peu plus compliqué : il faut d’abord installer nodejs puis yslow avant de pouvoir lancer la génération du rapport en passant par la génération d’un fichier HAR (HTTP ARchive) :
sudo /opt/nodejs/bin/npm install yslow -g
/opt/phantomjs/bin/phantomjs /opt/phantomjs/examples/netsniff.js <url page> | yslow
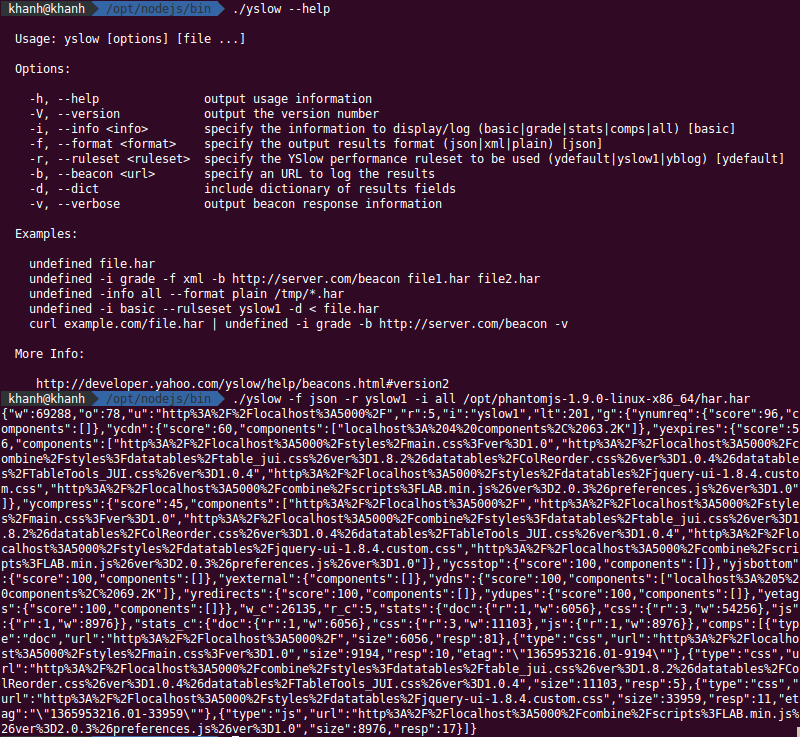
Coté génération du rapport Pagespeed, trois pistes ont été étudiées :
- la première en utilisant un module nodejs,
- la deuxième en compilant Pagespeed directement depuis le site de google,
- la troisième en s’appuyant sur un binaire déjà compilé trouvé sur le site de HarStorage.
Les deux premières solutions se sont malheureusement avérées être un échec : en effet, concernant le module nodejs, il s’est avéré être incompatible à l’installation avec la version courante de nodejs (0.10.4). Or une version antérieure se trouvait être incompatible avec le module YSlow… (j’avoue ne pas m’être amusé à tester toutes les versions de nodejs et j’ai donc laissé cette piste de coté).
Du coté de la deuxième piste, je n’ai malheureusement pas réussi à la faire compiler… :’( et cela malgré moultes tentatives sur les versions 1.7, 1.8 et 1.9 sur mon système Linux (Ubuntu 12.10) mais également sur un système disposant de XUbuntu 11.10. Cette piste a donc également été abandonnée…
La troisième tentative a, heureusement, été plus concluante. Ainsi, après téléchargement du binaire, il est possible, en lui fournissant un fichier HAR (générable, par exemple, à l’aide du module netsniff de phantomjs), de générer nos métriques PageSpeed :
/opt/phantomjs/bin/phantomjs /opt/phantomjs/examples/netsniff.js <url page> > monhar.har
./pagespeed_bin --input_file monhar.har
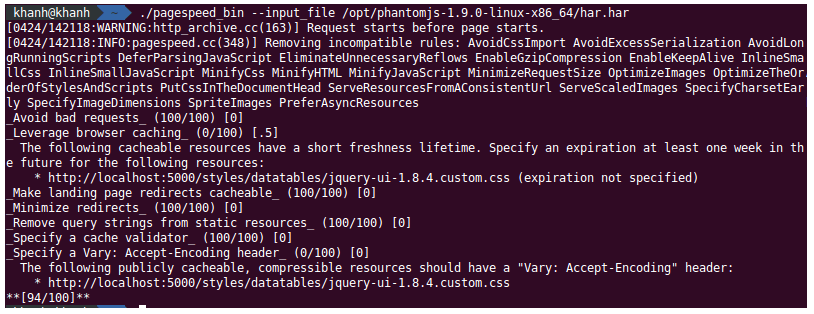
La génération des rapports ayant été effectuée, l’étape suivante pour répondre à notre cahier des charges consiste à remonter nos métriques récoltées par YSlow dans un outils un peu plus agréable.
Pour ce faire, le plugin TAP (Test Anything Protocol) de Jenkins a été utilisé. Ainsi, combiné avec l’exécution de récupération de la métrique, cela permet d’avoir au sein de Jenkins un job dédié à la génération de cette dernière et à son affichage, la gestion de l’historisation étant déléguée à l’historique du job.
Cependant, YSlow ne prenant en entrée qu’une url, un job doit être créé pour chaque page ciblée.
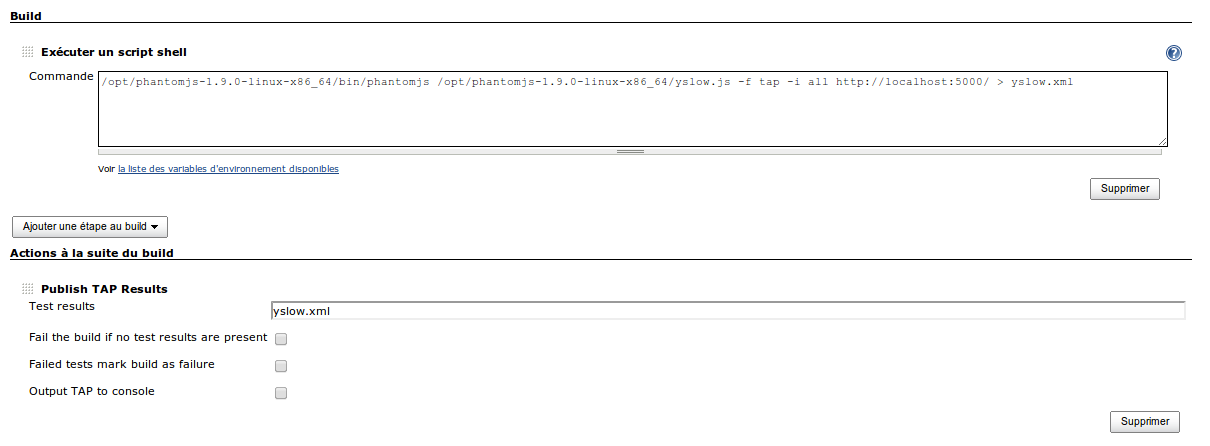
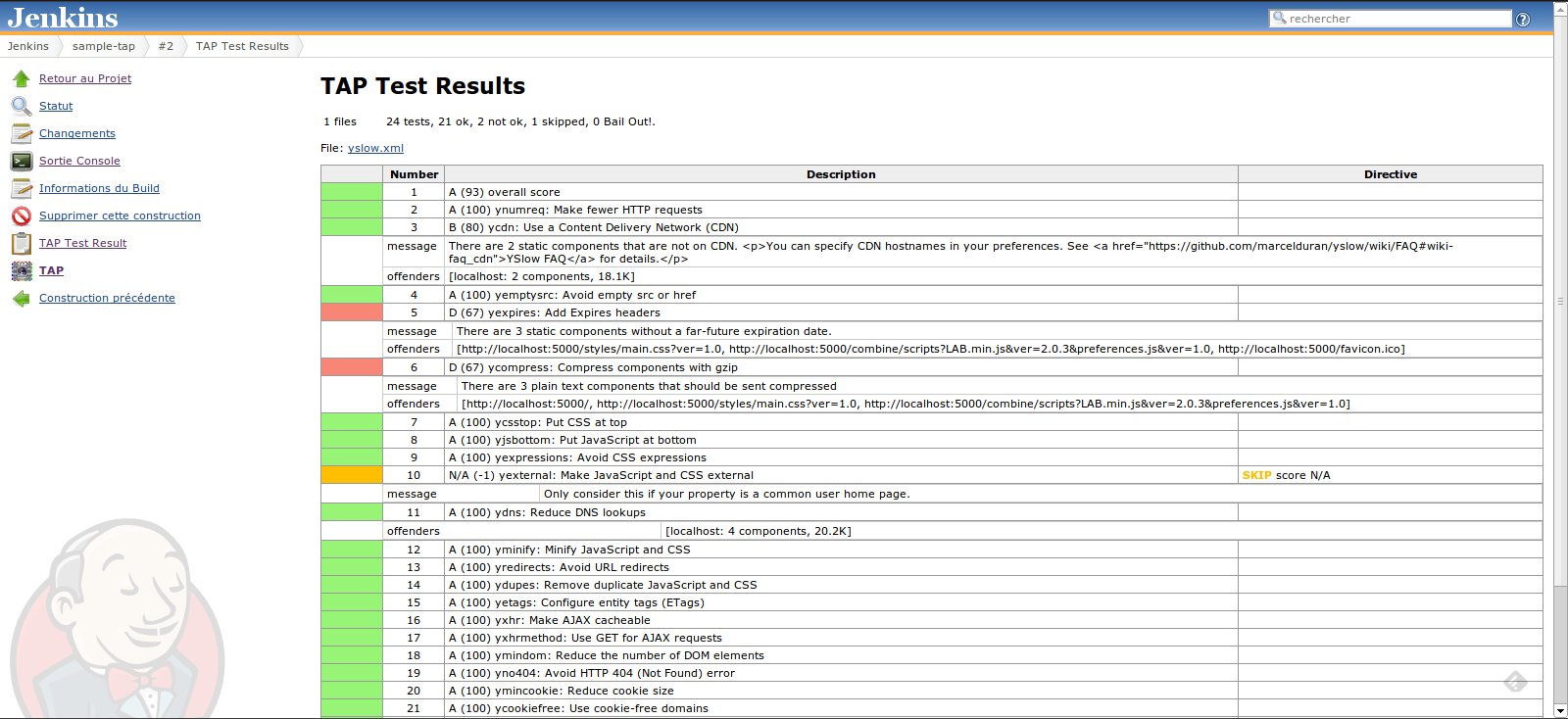
Coté Pagespeed, j’avoue ne pas avoir cherché mais le chapitre suivant proposera une solution simple et efficace pour obtenir une visualisation et une historisation de ces métriques.
Conclusion
Comme on a pu le constater, la génération de métriques YSlow et/ou Pagespeed oblige (je n’ai pas trouvé d’autres moyens plus simples :’( ) à passer par des frameworks tierces tels que phantomjs ou nodejs.
Pour le lecteur qui a su lire entre les lignes, il a pu constater qu’il y a deux approches possibles : soit passer par phantomjs (qui offre un navigateur headless) pour capturer la page rendu en déléguant au script de YSlow l’analyse de la page, soit passer par phantomjs pour générer un fichier HAR (qui contient, entre autre, les ressources chargées par la page ainsi que leur temps de récupération et le statut associé) puis de le passer à YSlow (via son module nodeJS) ou à PageSpeed.
En outre, du fait que les résultats obtenus l’ont été par page, pour un site complet, cela peut vite devenir… rébarbatif (pour rester poli)… pas glop…
Vitesse de rendu
Contexte
Dans la première partie, nous avons vu comment il était possible de générer des rapports d’exécution de bonnes pratiques d’une page HTML. Dans ce chapitre, nous nous intéresserons à la récupération de métriques de rendu d’une page au sens temps de récupération de ses différents éléments.
Comme précédemment, le problème peut être décomposé en deux étapes :
- la génération du rapport,
- sa représentation graphique pour une utilisation exploitable ainsi que son historisation.
Pour la partie génération, plusieurs pistes ont été étudiées :
- utilisation de phantomjs et de son plugin loadpage,
- utilisation de phantomjs et de son plugin netsniff (se trouvant dans le répertoire examples) pour générer un rapport HAR.
Coté affichage et historisation, nous verrons que cela a, encore une fois, été un peu galère même si les résultats obtenus sont satisfaisant (ouf… heureusement).
Solution et mise en oeuvre
La première piste étudiée a été celle utilisant le plugin loadpage.js de phantomjs :
/opt/phantomjs/bin/phantomjs /opt/phantomjs/examples/loadspeed.js <url page>

Cependant, ce plugin ne renvoie que le temps de chargement de la page et ne fournit pas un niveau de granulatité suffisante.
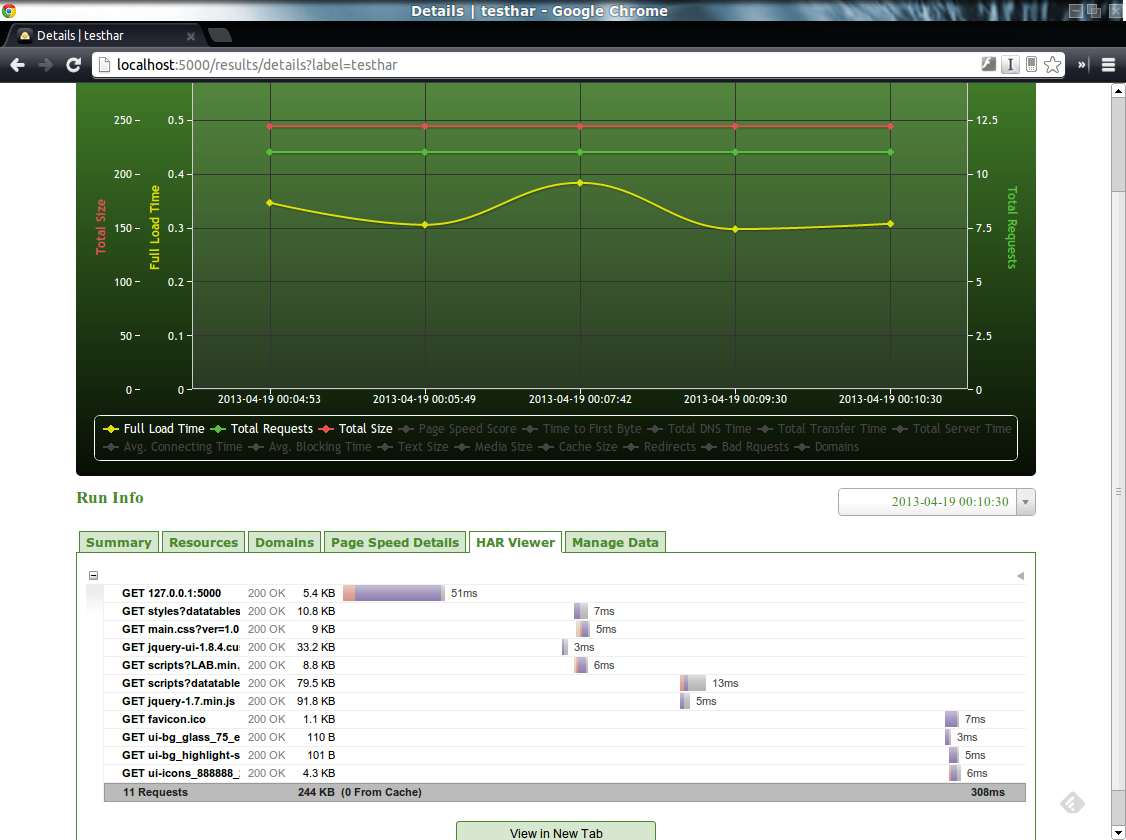
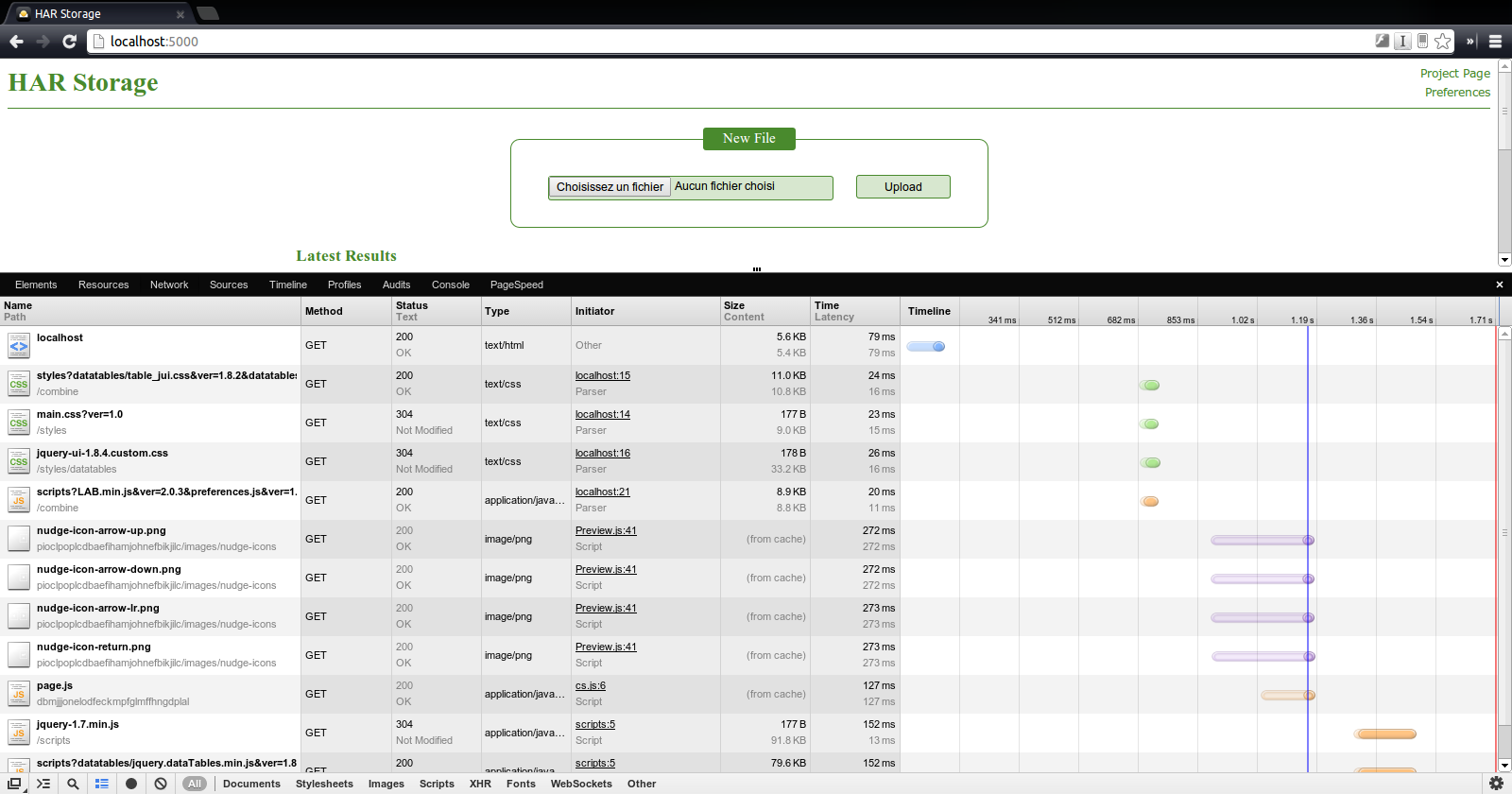
Le deuxième piste étudiée a été l’utilisation du plugin netsniff de phantomjs. Ce plugin permet de générer un fichier HAR (HTTP ARchive) qui contient l’ensemble des ressources chargées par la page ainsi que leur temps de chargement.
/opt/phantomjs/bin/phantomjs /opt/phantomjs/examples/netsniff.js <url page> > monFichier.har
Cette solution semble satisfaisante. Ne reste plus qu’à afficher le fichier HAR dans un dashboard…
Coté affichage, deux approches ont été testées :
- HarViewer,
- HarStorage.
HarViewer est un visualisateur de fichiers HAR. Il s’agit d’un programme ruby et demande donc une installation de ce dernier.
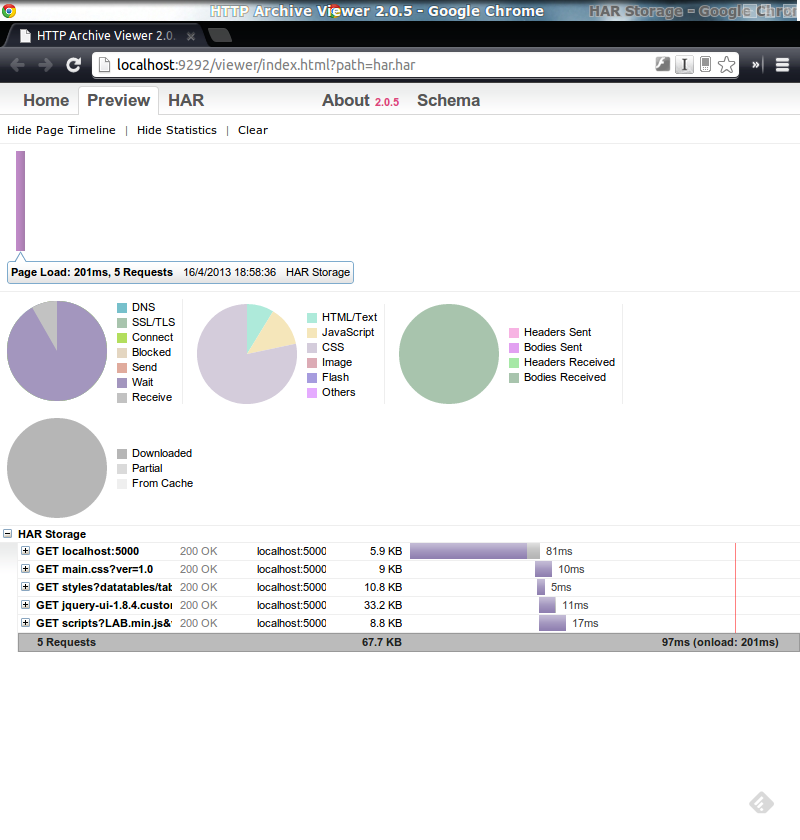
Cependant, il ne permet pas de suivre l’évolution d’une page dans le temps (pas de fonctionnalité d’historisation ni de comparaison)… dommage…
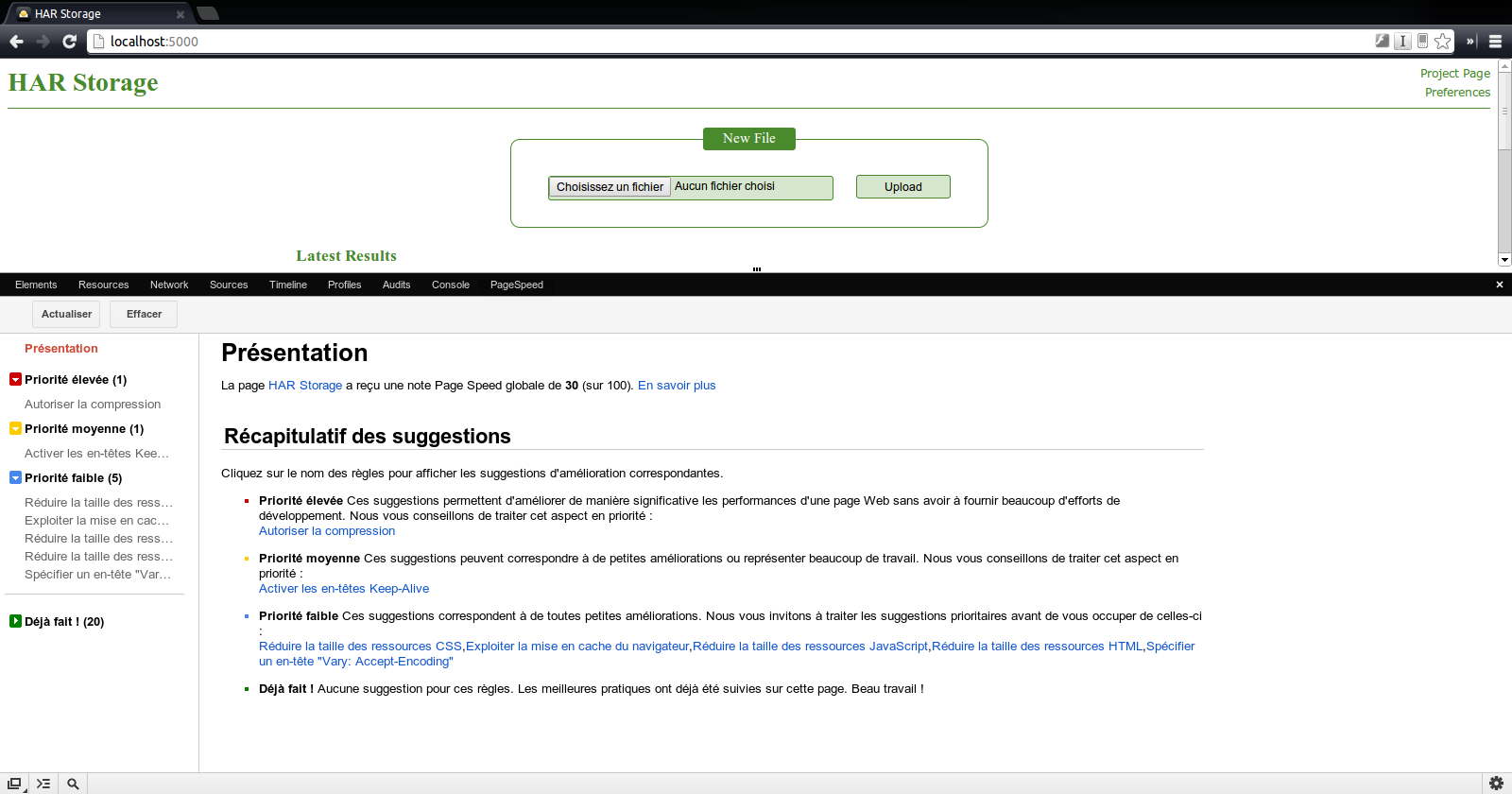
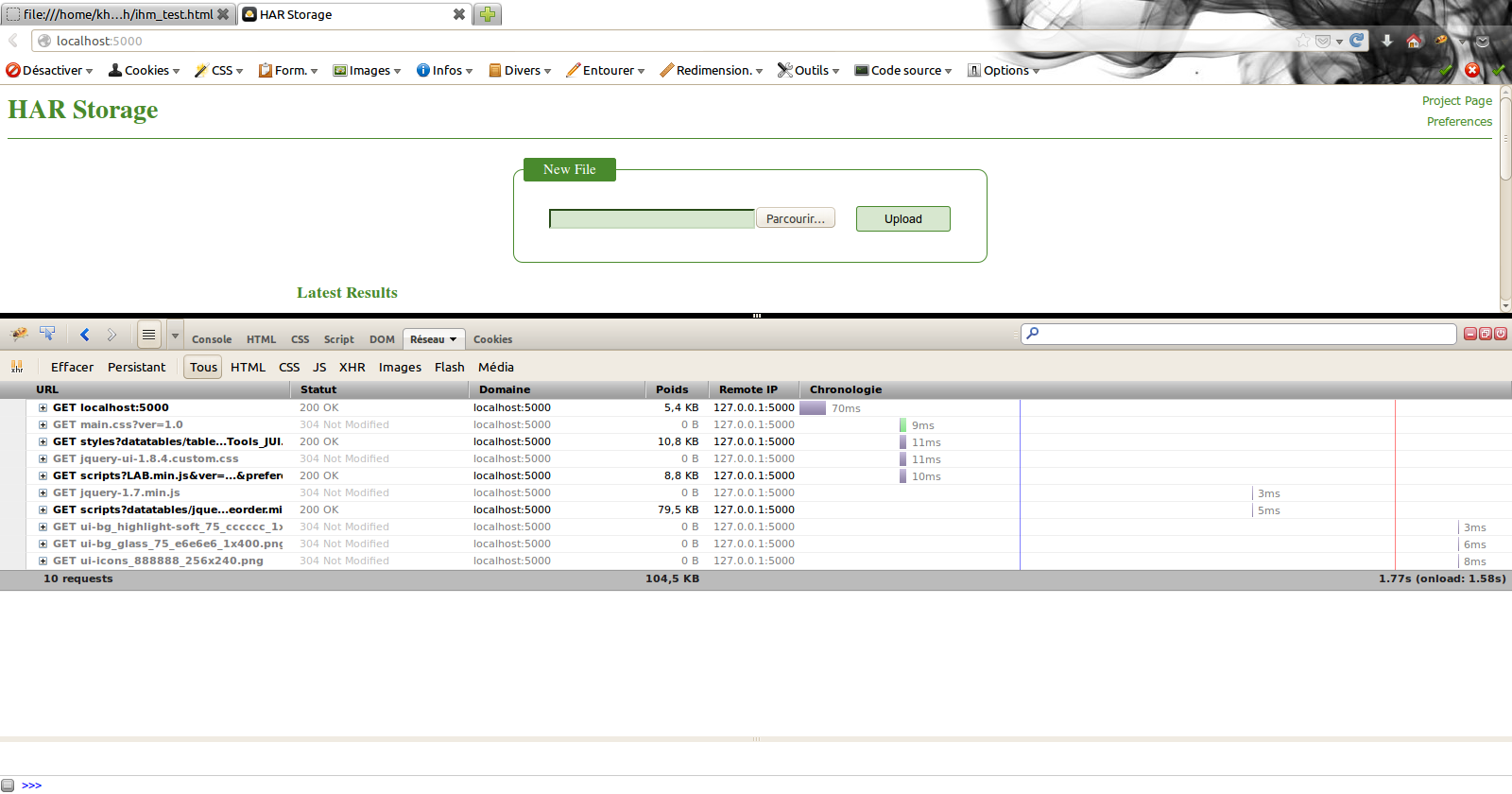
Du coté de HarStorage, son installation demande de nombreux autres composants (MongoDB, Python, …). Cependant, il offre une interface web par laquelle il est possible d’uploader ses fichiers HAR et, ainsi, d’en obtenir un stockage et donc, une historisation. Cerise sur la gateau, il offre également (modulo quelques manipulations) une génération et une visualisation des métriques PageSpeed.
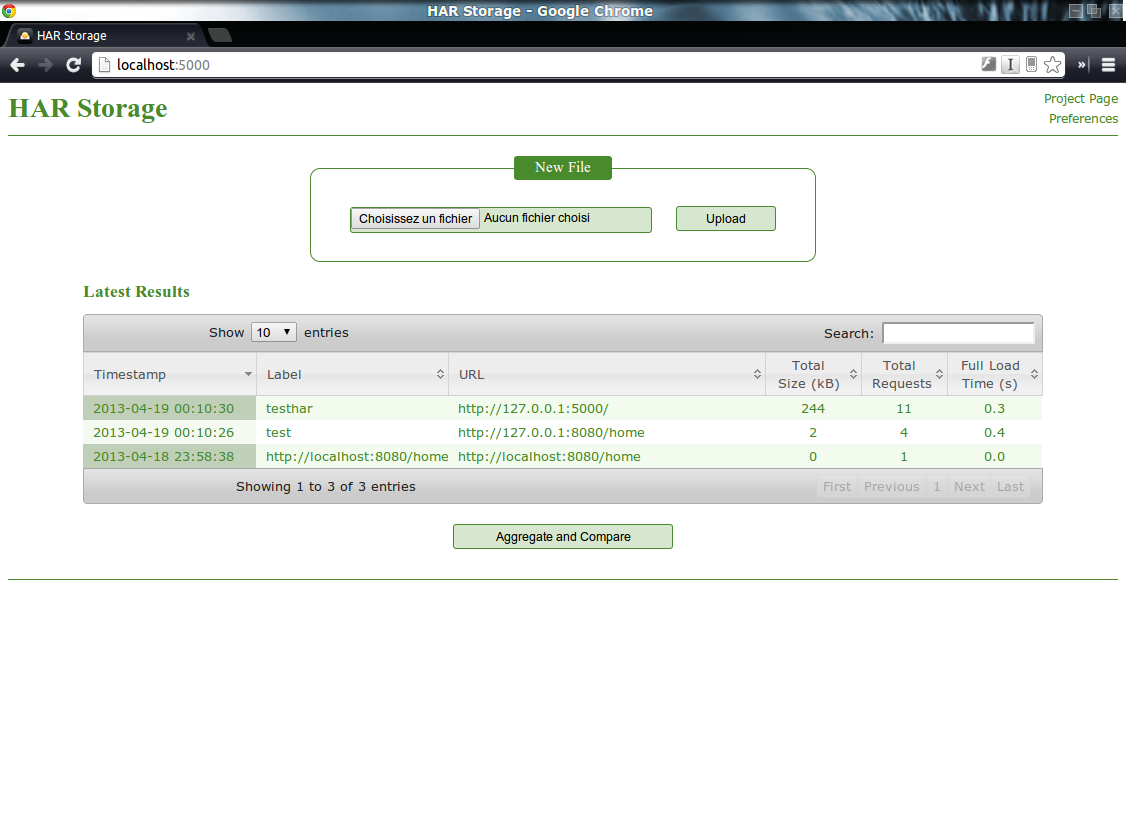
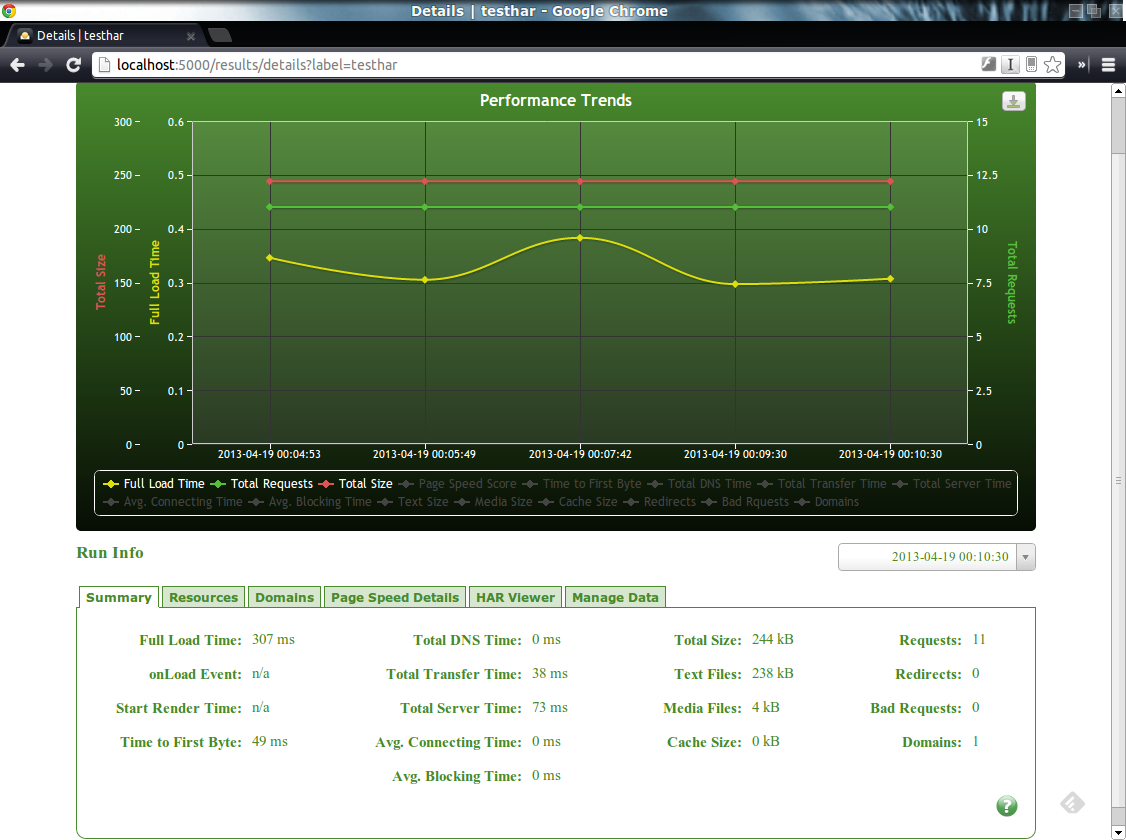
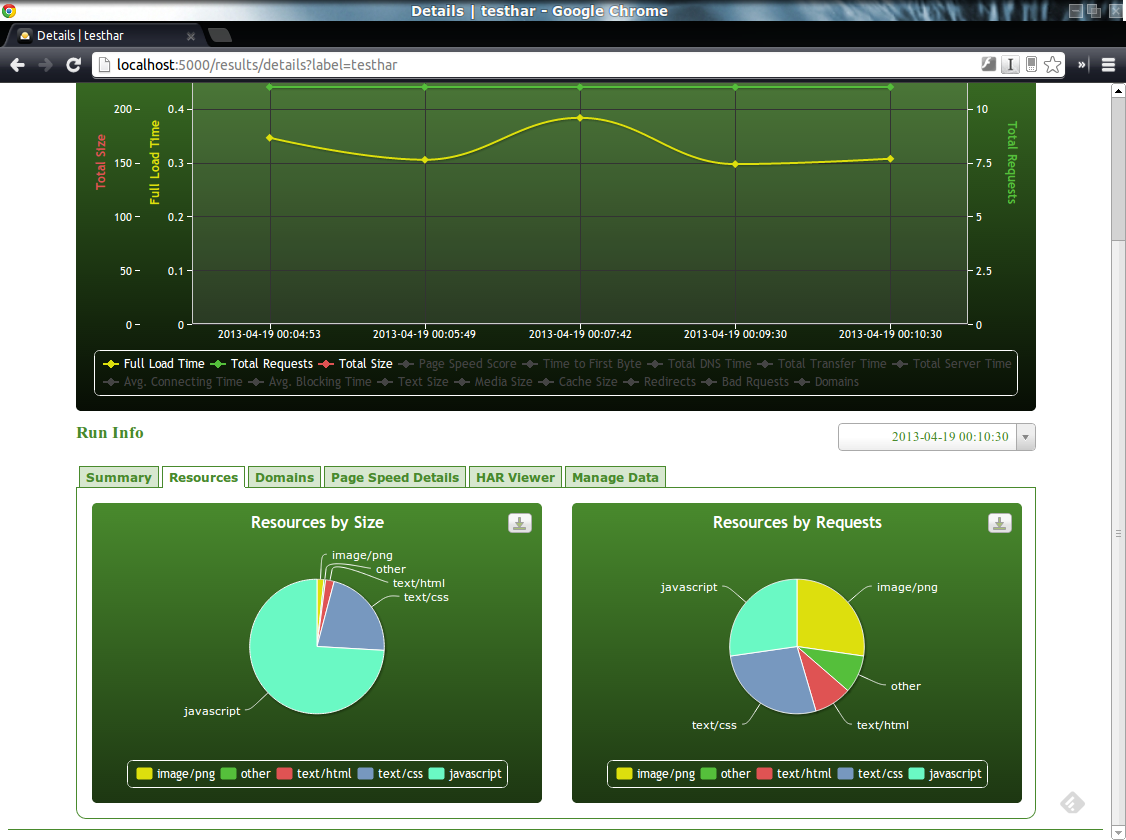
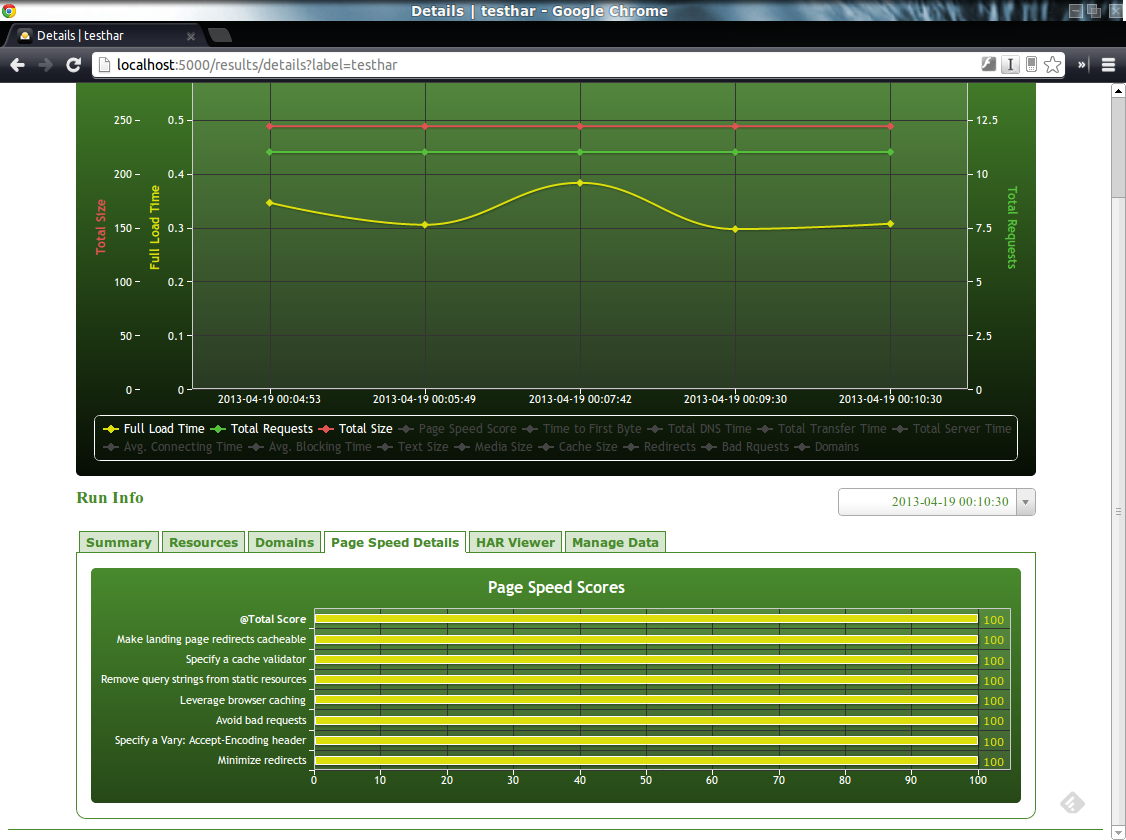
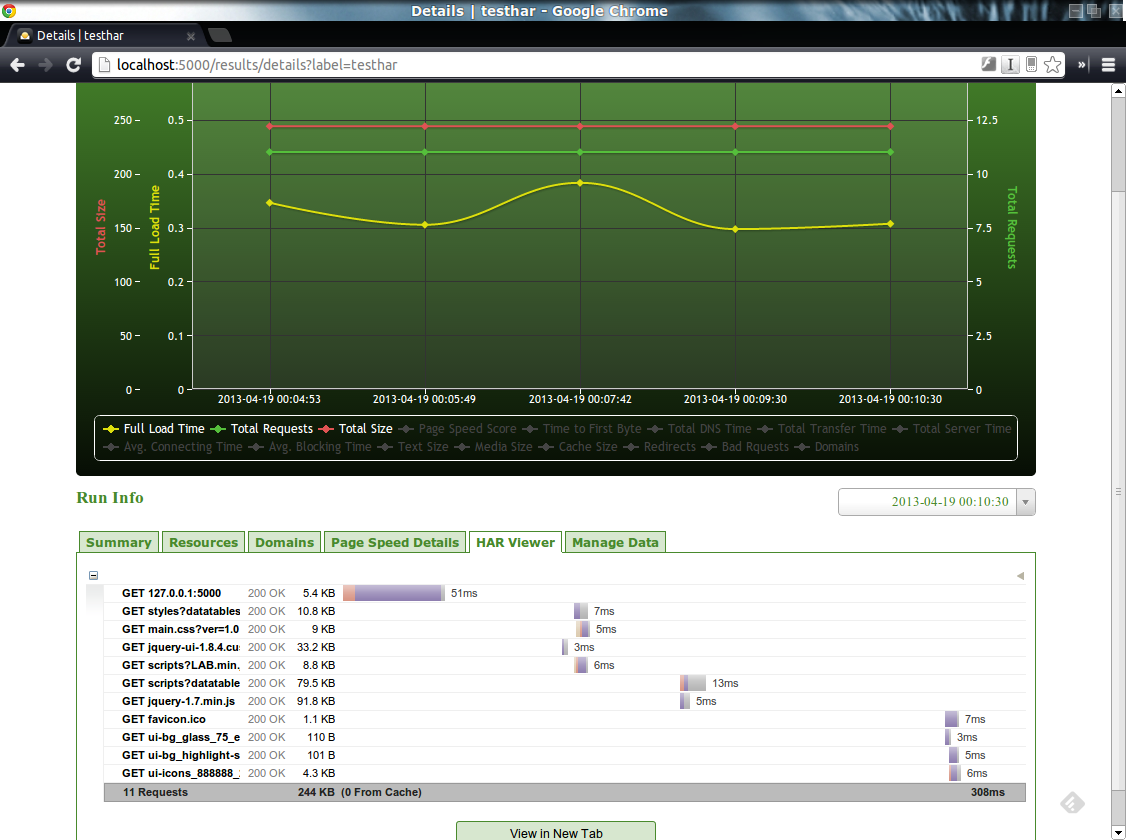
Conclusion
On a vu dans ce chapitre comment il était possible de générer et de visualiser des timeline de rendu de pages HTML. La solution HarStorage me semble, dans le cadre d’une phase d’industrialisation, la solution la plus aboutie en permettant de conserver un historique pour évaluer l’évolution de la page tout en fournissant un moyen de visualiser les métriques de PageSpeed (chose qui n’avait, pour rappel, pas été abordé dans le chapitre précédent).
Cependant, on a pu constater qu’il était nécessaire de faire pas mal d’actions : génération d’un fichier HAR puis upload manuel dans HarStorage ou exécution manuel de HarViewer.
En outre, le même constat peut être fait que pour le chapitre précédent : les résultats obtenus l’ont été par page… pas glop…
Automatisation totale
Contexte
On a vu dans les chapitres précédent comment générer des rapports au format HAR via phantomjs. Cependant, dans le cas où des tests d’acceptance sont déjà mis en place sur le projet via, par exemple, Selenium et Cucumber JVM, il peut être judicieux de se servir de l’existant pour intégrer la génération des rapports ainsi que la remonté de ces dernières dans l’outils de DashBoard.
Cela permet ainsi de faire une pierre deux coups, mais également d’éviter les étapes manuelles ou d’avoir à maintenir des jobs jenkins un peu trop techniques.
Solution et mise en oeuvre
Comme annoncé précédemment, l’objectif de ce chapitre est d’étudier la faisabilité d’intégration de la génération de rapport HAR et leur upload dans HarStorage avec notre trio Cucumber JVM/FluentLenium/Selenium.
En fait, il est possible d’automatiser la génération d’un rapport HAR à travers Selenium (et donc FluentLenium) en utilisant un proxy. Pour ce faire deux approches sont possibles :
- utiliser le proxy BrowserMobProxy de manière autonome,
- utiliser le proxy BrowserMobProxy de manière programmatique.
La partie upload au sein de HarStorage peut également être faite à l’aide des API Rest offertes par HarStorage.
Pour la première piste, je ne m’étendrai pas dessus puisque la solution est directement accessible sur le site de HarStorage. Il est juste important de noter que cette dernière nécessite d’avoir préalablement récupérer le proxy BrowserMobProxy en le compilant si nécessaire via un coup de mvn package -Preleasse (l’assembly se trouve branché au profil release) et de l’avoir lancé avec un port d’écoute donné, port qui est nommé PROXY_API_PORT dans le code :
./bin/browsermob-proxy --port 9090
En effet, BrowserMobProxy se comporte comme un serveur de proxy qu’il est possible de créer et d’enregistrer dynamiquement. Dans le code, la variable de classe PROXY_PORT correspond au port du proxy réel qui sera créé au sein du server BrowserMobProxy exécuté sur le port indiqué par PROXY_API_PORT. La classe fournit n’a pour rôle que d’interagir avec le serveur BrowserMobProxy au travers de son API REST (création d’un proxy, création et récupération du HAR).
La deuxième approche consiste, quant à elle, à créer ce serveur programmatiquement puis à lui demander l’instanciation d’un proxy Selenium (il n’y a donc pas besoin de récupérer le serveur BrowerMobProxy).
ProxyServer server = new ProxyServer(Integer.valueOf(PROXY_API_PORT));
server.start();
// Change browser settings
Proxy proxy = server.seleniumProxy();
////////////////////////////////////////////////
// ip a renseigner soit manuellement soit en utilisant NetworkInterface
////////////////////////////////////////////////
String ip = "";
proxy.setHttpProxy(ip + ":" + PROXY_API_PORT);
proxy.setHttpProxy(ip + ":" + PROXY_API_PORT);
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability(CapabilityType.PROXY, proxy);
Driver firefoxDriver = new FirefoxDriver(capabilities)
server.newHar(name);
////////////////////////////////////////////////
// ma navigation via selenium avec le driver
////////////////////////////////////////////////
// Read data from container
Har har = server.getHar();
String strFilePath = "target/selenium_report.har";
File file = new File(strFilePath);
if (file.exists()) {
file.delete();
}
FileOutputStream fos = new FileOutputStream(file);
har.writeTo(fos);
server.stop();
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(file) );
LineNumberReader lineNumberReader = new LineNumberReader(inputStreamReader);
String ligne;
String res = "";
while ((ligne = lineNumberReader.readLine()) != null) {
res += ligne;
}
// Send results to HAR Storage
try {
HarStorage hs = new HarStorage(HARSTORAGE_HOST, Integer.toString(HARSTORAGE_PORT));
String response = hs.save(res);
System.out.println(response);
} catch (Exception e) {
e.printStackTrace();
}
Par contre, il semble que le driver de phantomjs ne fonctionne pas… dommage…
Bien sûr, cela est parfaitement intégrable à ce qui a été fait dans mon article précédent (ie. via Cucumber JVM et FluentLenium), ce qui permet d’obtenir une feature Cucumber JVM du type :
Feature: harstorage
Scenario Outline: har browser navigation:
Given I connect on url http://127.0.0.1:8080 with different browsers and I register the HarStorage Server on 127.0.0.1:5000 with name test:
| <browser> | <parameters> | <host> | <version> | <platform> |
Given j accede a la homePage
And je suis sur homePage
When je submit
Then je suis sur la page result
Then I send har files to the HarStorage Server
Then drivers are closed
Examples:
| browser | parameters | host | version | platform |
| firefox | | none | | |
# | firefox | | http://10.147.2.83:4444/wd/hub | | win7 |
Conclusion
On a vu dans ce paragraphe qu’il était aisé d’intégrer la génération et l’upload d’un fichier HAR issu d’un scénario fonctionnel dans HarStorage.
Cependant, ce mécanisme ne fonctionne malheureusement pas avec phantomjs, ce qui peut forcer à l’utilisation de Selenium Server (à noter que cela n’a pas été testé avec d’autres driver que Firefox).
Enfin, un point essentiel à noter est que par cette méthode, le temps d’exécution du javascript n’est pas remonté dans la timeline. En effet, l’utilisation d’un proxy ne fournit pas cette information alors qu’avec une génération direct d’un fichier HAR via phantomjs, cette donnée est bien présente.
Conclusion
Cet article a montré (enfin je l’espère…) comment il était possible d’automatiser la génération de métrique de rendu des pages HTML dans une usine logicielle .
C’est vrai que de nombreuses technologies/manipulations sont nécessaires alors qu’il existe de nombreux(?) services qui rendent le même service (GTMetrix, WebPageSpeed, …).
Malheureusement, ces services ne sont généralement branchées qu’en production (pas d’accès aux serveurs de tests/intégrations des entreprises) alors que les avoir au plus tôt dans le cycle de développement permettrait de minimiser les risques de régression et surtout de pousser à avoir une meilleure qualité telle que nous le permet Sonar.
Je tiens tout de même à préciser que j’ai été déçu de ne pas trouver une solution plus simple d’intégration de ces outils dans nos usines de développement.
Cela pourrait s’expliquer par un manque de maturité de l’environnement Java pour faire du Web 2.0 (sic) ou par une mutation du métier de développeur web qui tendrait vers une meilleure qualité logicielle mais qui n’aurait pas encore assimilé/intégré toutes les contraintes induites par une usine logicielle telle que celles que l’on connait dans notre monde Java… enfin, en gros, il reste du boulot…
Pour aller plus loin…
-
YSlow : http://yslow.org
-
PageSpeed : https://code.google.com/p/page-speed
-
HarViewer : https://github.com/jarib/har
-
HarStorage : https://code.google.com/p/harstorage/
-
BrowserMobProxy : http://opensource.webmetrics.com/browsermob-proxy/
-
Jenkins TAP Plugin : https://wiki.jenkins-ci.org/display/JENKINS/TAP+Plugin
-
CucumberJVM : https://github.com/cucumber/cucumber-jvm
-
FluentLenium : https://github.com/FluentLenium/FluentLenium
-
Selenium : http://docs.seleniumhq.org/
-
PhantomJS : http://phantomjs.org/
-
NodeJS : http://nodejs.org/
-
http://www.igvita.com/2012/08/28/web-performance-power-tool-http-archive-har/
-
http://fr.slideshare.net/watsonmw/performance-monitoring-in-a-day
-
code du POC : https://github.com/jetoile/fluentlenium-cucumber/tree/harStorage